
Entity SEO (سئو انتیتی) چیست؟
انتیتی در سئو چیست؟
چرا سئو انتیتیمحور (Entity-Based SEO) مهم است؟
چطور باید محتواها را برای انتیتیها بهینه کرد؟
آیا سئو سایت بهکلی متحول شده است؟
آیا مدیران و کارشناسان سئو سایت باید استراتژیهای متفاوتی را دنبال کنند؟
رفتارهای کاربران وقتی میخواهند چیزی را جستجو کنند تغییر کرده است. موتورهای جستجو هم تغییر کردند.
هوش مصنوعی و ورود موتورهای پاسخگو و مولد که مبتنی بر هوش مصنوعی کار میکنند، سئو سایت را متحول کرده است.
دیگر اولین انتخاب همهی کاربران اینترنت گوگل نیست. بسیاری ترجیح میدهند که از چت جی پی تی بخواهند تا سؤالی را پاسخ دهد.
بله، سئو سایت بهکلی تغییر کرده است و این تغییر ادامه دارد.
دیگر سئو سایت بهتنهایی کافی نیست و به بهینهسازی وبسایت برای موتور مولد (GEO) Generative Engine Optimization هم نیاز است.
به همین دلیل است که برای سئو محتوا به دانش و تکنیکهای جدید نیاز است.
آن دانش و تکنیک جدید و ضروی برای سئو محتوا در سال ۲۰۲۴ و آینده، سئو انتیتی است.
این راهنمای جامع دربارهی سئو انتیتیمحور است و به همهی سؤالات دربارهی این موضوع جدید و مهم پاسخ میدهد.
راهنمایی که میخوانید براساس راهنمای وبسایتهای مرجع در سئو سایت، Search Engine Land، Search Engine Journal و ahrefs نوشته شده است.
آنچه در این نوشته خواهیم داشت
سئو موجودیت چیست؟
در این مطلب به همهی موضوعاتی که باید دربارهی Entity (موجودیت یا یک واحد وجودی) بدانید، پرداخته شده است: Entity چیست، چرا در سئو مهم است و چگونه باید از موجودیتها برای رتبهآوردن محتوا استفاده کرد.
«چیزها، نه رشتهها».
اگر با این عبارت آشنا نیستید، باید بگوییم که این عبارت از بلاگ پست گوگل در سال ۲۰۱۲ آمده است. در این محتوای معروف گوگل از Knowledge Graph رونمایی کرد.
از عمر این پست دوازده سال میگذرد و بسیاری هنوز تلاش میکنند تا بفهمند «چیزها، نه رشتهها» واقعا به چه معنا است.
این نقلقول تلاشی برای انتقال این مفهوم است که گوگل مفاهیم را درک میکند و دیگر فقط یک الگوریتم ساده برای تشخیص کلمات کلیدی نیست.
بر همین اساس است که میتوان ادعا کرد که سئوی موجودیتها در سال ۲۰۱۲، همزمان با انتشار آن محتوا و تمرکز بر جستجوی معنایی گوگل و سمنتیک سئو یا سئو معنایی متولد شد.
یادگیری ماشینی گوگل، با کمک پایگاههای دانش نیمهساختاریافته و ساختاریافته، میتواند معنای پشت یک کلمهی کلیدی را درک کند.
بهعبارتدیگر، سرانجام، راهحلی بلندمدت برای حل معضل ماهیت مبهم زبان پیدا شده است.
سئوی مبتنیبر موجودیت رویکردی در بهینهسازی وبسایت برای موتورهای جستجو است که در آن بهجای تکیه بر کلمات کلیدی، بر مفهوم موجودیتها بهعنوان عنصر مرکزی محتوا تمرکز میشود.
یک موجودیت ممکن است هر چیزی، یک شخص، مکان، سازمان، برند، مفهوم یا ایده، باشد. ویژگی موجودیت این است که منحصربهفرد است و قابلشناسایی و تمایز از دیگر موجودیتها. همچنین هر موجودیت را میشود واضح و کوتاه تعریف کرد.
هر کدام از موارد زیر یک موجودیتاند:
- بیل کلینتون،
- رستوارن نایب،
- آکادمی آمانج،
- شهرداری تهران،
- مارکسیسم،
- توسعهی پایدار،
- فیزیک کوانتوم و
- تولید محتوا.
در این روش برای سئو بر درک و بهینهسازی معانی پشت کلمات کلیدی (که همان موجودیتها است) تأکید میشود. چون موتورهای جستجو، بهویژه گوگل، میتوانند موجودیتها را تشخیص دهند و برای فهمیدن زمینه و قصد جستجوی کاربران استفاده کنند.
در سئو سنتی که مبتنیبر کلمات کلیدی است، تمرکز اصلی بر بهینهسازی محتوا و وبسایت برای کلمات یا عباراتی است که کاربران ممکن است در نوار جستجوی موتور جستجو بنویسند.
اما سئوی مبتنیبر انتیتی یک گام فراتر میرود و بهینهسازی برای زمینهای را که آن کلمات کلیدی در آن استفاده میشوند نیز دربرمیگیرد.
گوگل با درنظرگرفتن هدف جستجو و روابط بین موجودیتهای مختلف، زمینهای را که هر کلمه یا عبارت کلیدی در آن کاربرد دارد (بهعبارتدیگر، بافت یا سیاق کلام یا متن) میفهمد.
بهعبارتدیگر، رویکرد موجودیتمحور به سئو سایت به این دلیل اهمیت پیدا کرده است که موتورهای جستجو برای درک عمیقتر هدف جستجوگر و بافت کلام تکامل یافتهاند.
چرا کارشناسان سئو سایت باید دربارهی سئو انتیتیمحور بدانند؟
موجودیتها بیشاز یک دهه است که برای گوگل مهم شدهاند. اما چرا متخصصان سئو هنوز دربارهی موجودیتها سردرگماند؟
سؤال خوبی است که باید پاسخی برای آن یافت.
چهار دلیل را میشود برای پاسخ به آن سؤال ذکر کرد:
- اصطلاح سئوی موجودیت بهاندازهی کافی در بین متخصصان سئو رایج نشده است تا به آن بپردازند و درنتیجه آن را در واژگانشان بگنجانند.
- بهینهسازی برای موجودیتها تا حد زیادی با روشهای قدیمی بهینهسازی که متمرکز بر کلمات کلیدی است، همپوشانی دارد. پس، موجودیتها با کلمات کلیدی ترکیب میشوند. علاوهبراین، هنوز کاملا مشخص نیست که موجودیتها چگونه در سئو نقشآفرینی میکنند. گوگل نیز گاهی اوقات از کلمهی «موضوعات» بهجای «موجودیتها» استفاده میکند.
- درک موجودیتها کاری خستهکننده است. اگر کارشناسان سئو میخواهند دانش عمیقی دربارهی موجودیتها داشته باشند، لازم است دربارهی بعضی از اختراعات گوگل بخوانند و اصول اولیهی یادگیری ماشین را بدانند. سئوی موجودیت رویکردی بسیار علمیتر به سئو است و همهی کارشناسان سئو سایت به مباحث علمی علاقه ندارند.
- یوتیوب بر توزیع دانش تأثیر گستردهای گذاشته است، اما یادگیری بسیاری از موضوعات را بیشازحد ساده کرده است. تولیدکنندگان محتوا که در این پلتفرم موفقتریناند، در آموزش مخاطبان خود سادهترین مسیر را انتخاب کردهاند. بنابراین، نیازی نداشتند تا زمان زیادی را برای تولید محتوای آموزشی دربارهی موجودیتها کنند. بههمیندلیل، الان و برای یادگیری اصولی دربارهی موجودیتها باید از متخصصان NLP (پردازش زبان طبیعی) کمک گرفت و آموخت و سپس آن دانش را در سئو پیاده کرد.
چرا موجودیتها در سئو سایت مهماند؟
سئوی موجودیت آیندهی سئو و راهکار نهایی موتورهای جستجو است برای تعیین معنای محتوا و انتخاب محتوایی که باید به کاربران نشان داده شود.
انتیتیها به این دلیل در سئو سایت مهماند چون دلیلی هستند برای اینکه
- موتورهای جستجو بهتر مفهوم و قصد جستجوهای کاربران را درک کنند و در انتخاب نتایج جستجو دقیقتر و هدفمندتر باشند.
- نتایج جستجو براساس معنا و مفاهیم مرتبط با قصد و هدف کاربر نه فقط تطابقبا کلمهکلیدی به او ارائه شود.
- کاربر بهجای وقتگذاشتن و جستجو در صفحات مختلف از نتایج، اطلاعات دقیق و جامع دریافت میکند.
- موتوهای جستجو در پاسخدادن به جستجوهای صوتی بهتر عمل کنند چون کاربر سؤالش را بهزبان طبیعی و محاورهای میپرسد.
قبلاز بحث و توضیح بیشتر برای روشنکردن اهمیت موجودیتها در سئو لازم است اشاره کنیم که موتور جستجوی گوگل و الگوریتمهای آن چه نیازی به موجودیتها دارند.
بههمیندلیل، ابتدا به چند موضوع مهم و مرتبط اشاره میکنیم: اول، چند نمونه از کارکرد موجودیتها را در وب میبینیم، بعد به اهمیت موجودیت میپردازیم و درنهایت دربارهی محدودیت الگوریتمهای گوگل در درک موجودیتها توضیح میدهیم.
بهتر است نمونههایی از موجودیتها را باهم بررسی کنیم تا ببینیم که یافتن و تشخیص موجودیتها اصلا کار سختی نیست. در SERP گوگل چندین نمونه از موجودیتها را دیدهاید.
رایجترین انواع موجودیتها به مکانها، افراد یا مشاغل مربوط میشوند.
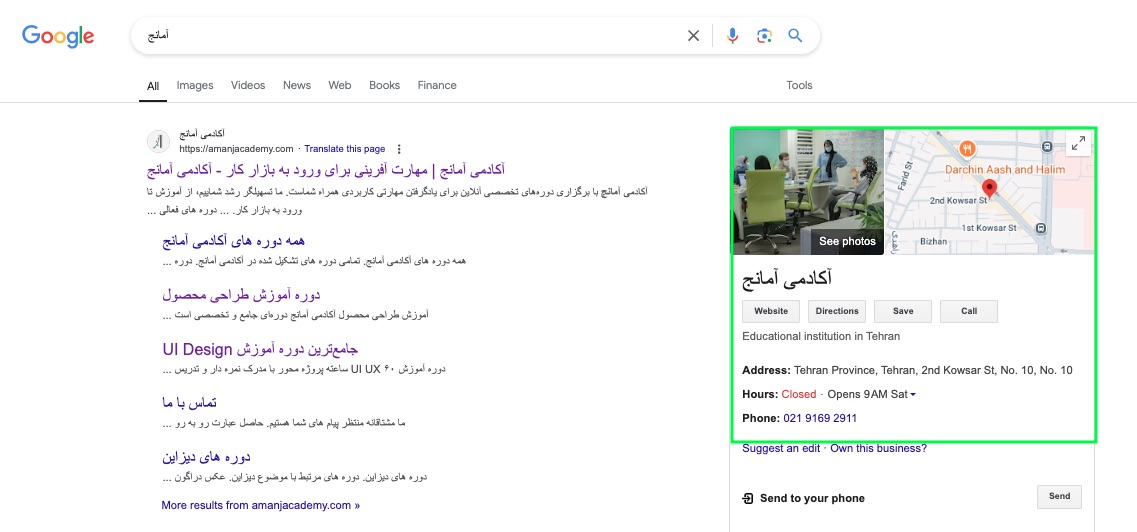
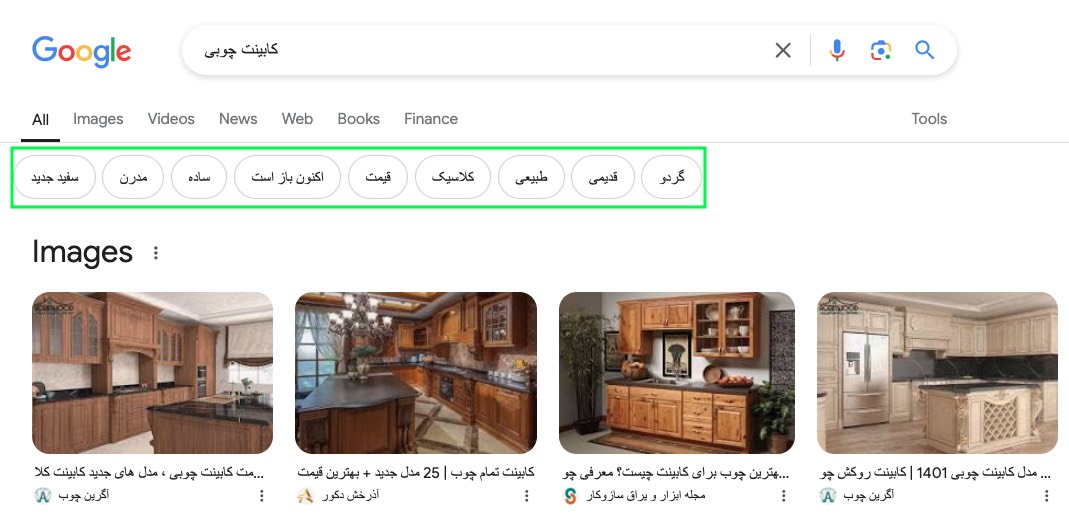
شاید بهترین مثال از موجودیتها در SERP دستهها یا خوشههای معنایی (intent clusters) است که در تصویر بالا و دو تصویر پایین در کادر سبز میبینید.
هرچه الگوریتمهای گوگل یک موضوع را بیشتر درک کرده باشند، دستههای معنایی در نتایج جستجو بیشتر نمایان میشوند. در تصاویر زیر، تفاوت در تعداد دستههای معنایی نشان میدهد که الگوریتمهای گوگل انتیتی حقوق را بهتر درک میکنند.
جالب اینجا است که یک کمپین سئو ممکن است حتی شکل SERP را تغییر دهد، البته زمانیکه کارشناسان سئو و دیجیتال مارکترها بدانند چگونه کمپینهای سئوی متمرکز بر موجودیت را اجرا کنند.
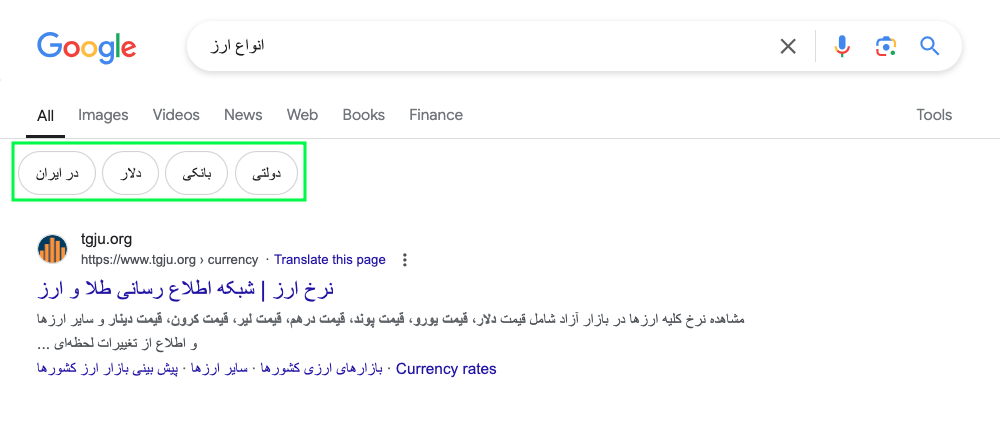
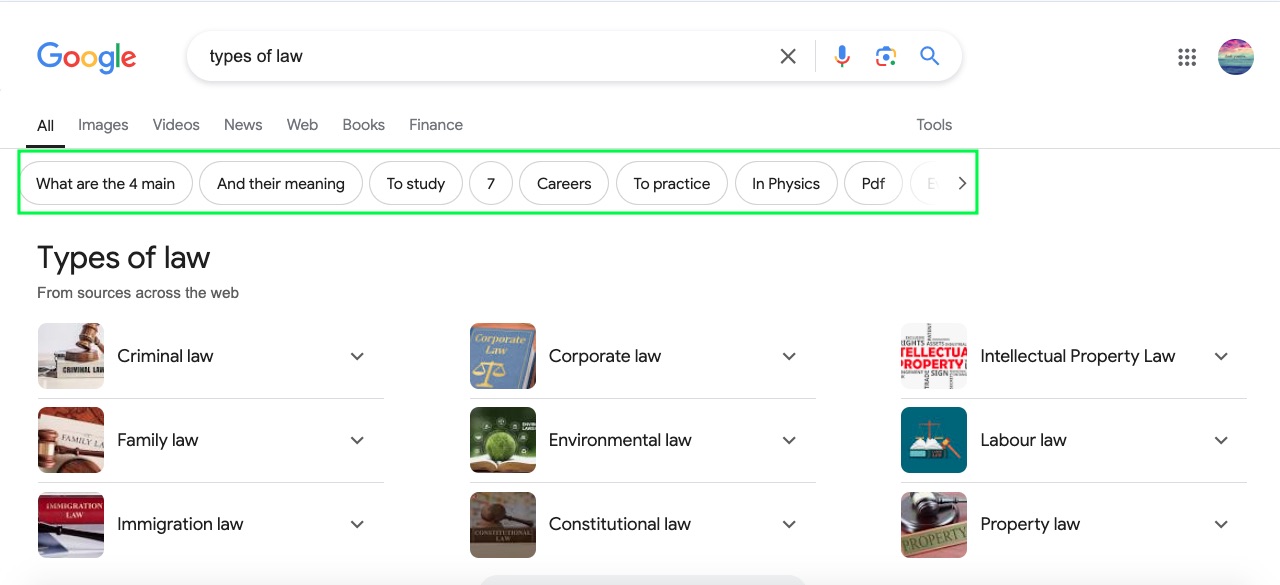
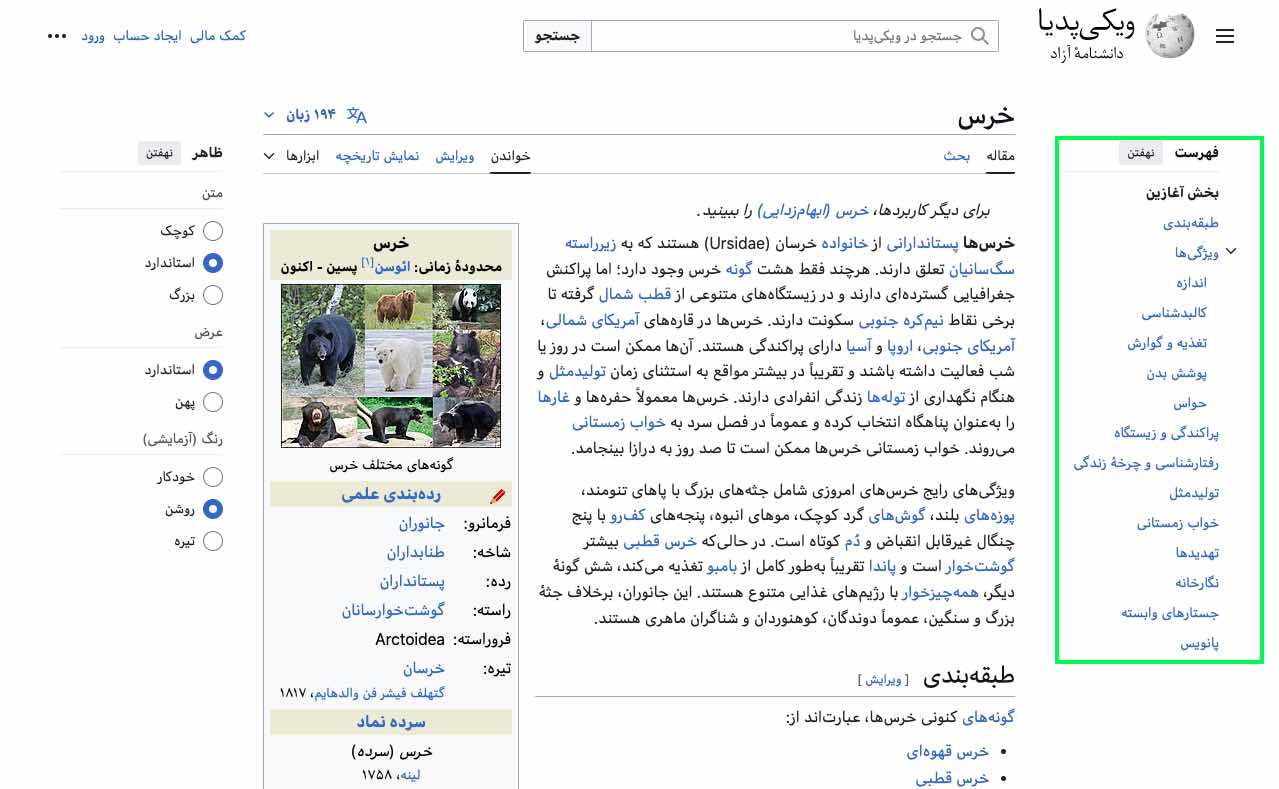
ویکیپدیا نمونهی دیگری از موجودیتها است. ویکیپدیا نمونهی بسیار خوبی از دستهبندی اطلاعات براساس موجودیتها را ارائه میدهد.
همانطورکه در فهرست (کادر سبز) مشاهده میکنید، فهرست ویکیپدیا انواع مختلف ویژگیهای مرتبطبا خرس، از آناتومی آن گرفته تا اهمیتش برای انسان را شامل میشود.
البته، باید به این نکته توجه کرد که ویکیپدیا بسیاری از دادههای مرتبط به یک موضوع را دارد، اما آن دادهها بههیچوجه جامعوکامل نیست. همچنین، ویکیپدیا تنها مرجع تعیینکننده در وب نیست که آیا چیزی یک موجودیت است یا خیر. اما درهرحال ویکیپدیا را پایگاه دادهای برای موجودیتها بهشمار میآورند.
انتیتیها برای موتورهای جستجو چه اهمیتی دارند؟
گفتیم که یک موجودیت یا واحد وجودی شی یا چیزی منحصربهفرد و قابلشناسایی یا مفهوم و ایدهای است که با نام، نوع، ویژگیها و ارتباطش با موجودیتهای دیگر متمایز میشود.
موجودیتها در یک فهرست (کاتالوگ) موجودیت ثبت میشوند. فهرستهای موجودیت به هر موجودیت یک شناسه میدهند.
اگر یک کلمه یا عبارت در یک فهرست موجود نباشد، به این معنی نیست که آن کلمه یا عبارت یک موجودیت نیست. اما معمولا میشود با دیدن نام چیزی در کاتالوگ موجودیتها مطمئن شد که آن یک موجودیت محسوب میشود.
چند نمونه از فهرستهای موجودیت عبارتاند از:
- Wikipedia
- Wikidata
- Yago
این فهرستها درحقیقت یک نوع پایگاه دانشاند.
پایگاه دانش مخزن متمرکزی از اطلاعات ساختاریافته و ساختارنیافته است که برای دسترسی آسان، مدیریت و بازیابی دانش سازماندهی شده است. پایگاه داده برای ذخیره و مدیریتکردن دادهها، بینشها و راهحلها استفاده میشود و منبعی برای استخراج داده برای انسانها و ماشینها است.
پایگاههای دانش به دو نوع تقسیم میشوند:
- پایگاههای دانش برای خواندن انسان (Human-Readable Knowledge Bases): این نوع پایگاههایی هستند که انسانها میتوانند دادههایش را بخوانند و استفاده کنند. ویکیپدیا یک نمونه از این پایگاه دانش است. سازمانهای بزرگ نیز برای ذخیرهکردن پاسخ به پرسشهای متداول، مستندات محصول و راهنمایی استفاده از محصولات برای کارمندان خود پایگاه دانش درست میکنند.
- پایگاههای دانش برای خواندن ماشینها (Machine-Readable Knowledge Bases): مخاطب این پایگاه داده ماشینها (هوش مصنوعی یا موتورهای جستجو) است. دادهها در این نوع پایگاه دانش ساختاریافته و برای پردازش الگوریتمها بهینهسازی و دخیره میشوند. گراف دانش گوگل و IBM Watson ازجمله مهمترین و شناختهشدهترین پایگاههای دانش برای ماشینها محسوب میشوند.

هر دو نوع پایگاه دانش ویژگیهای مشترکی دارند:
- مکان واحدی برای ذخیرهی متمرکز و مدیریت مجموعههایی متنوع از اطلاعاتاند.
- دادهها به دو صورت، دادههای ساختاریافته و ساختارنیافته، در پایگاه ذخیره میشوند.
- اطلاعات را میشود سریع در یک پایگاه دانش بازیابی کرد.
- برای جستجو و بازیابی آسانتر در میان اطلاعات، محتواها طبقهبندی شدهاند.
اهمیت اصلی موجودیتها در این است که با کمک انتیتیها، شکاف بین دنیای دادههای ساختارنیافته و ساختاریافته در پایگاه دانش پر میشود.
ویدئوها، پادکستها، تمامی محتواهای بلاگ وبسایتهای مختلف، ازجمله همین محتوایی که میخوانید، همه در دستهی دادههای ساختارنیافته قرار میگیرند.
نکته اینجا است که ماشینها، ازجمله الگوریتمهای گوگل، نمیتوانند دادههای ساختارنیافته را بخوانند و بفهمند. داده ساختارنیافته باید ساختاریافته شود تا ماشین آن را پردازش کند.
دادههای ساختاریافته دادههایی است که درقالبی ذخیره میشود که ماشینها بتوانند پردازششان کنند و آنها را بفهمند.
دادههای ساختاریافته در قالبهای مشخص مانند جدول و نمودار یا فرمتهای JSON، XML و … تعریف میشوند.
دادههای زیر نمونههایی از دادههای ساختاریافته است که کدهای اسکیمای محتواهای دو صفحه از دو وبسایت مختلف هستند.
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Restaurant",
"name": "رستوران گلسرخ",
"address": {
"@type": "PostalAddress",
"streetAddress": "خیابان ولیعصر، پلاک ۱۲",
"addressLocality": "تهران",
"addressCountry": "ایران"
},
"telephone": "+98-21-12345678",
"priceRange": "$$",
"servesCuisine": ["ایرانی", "گیاهی"],
"openingHours": [
"Mo-Sa 11:00-23:00",
"Su 12:00-20:00"
]
}
</script>
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Book",
"name": "The Great Gatsby",
"author": {
"@type": "Person",
"name": "F. Scott Fitzgerald"
},
"publisher": {
"@type": "Organization",
"name": "Scribner"
},
"datePublished": "1925-04-10",
"isbn": "9780743273565",
"numberOfPages": 218,
"inLanguage": "en",
"genre": "Fiction",
"description": "A novel set in the 1920s that explores themes of wealth, love, and the American Dream.",
"aggregateRating": {
"@type": "AggregateRating",
"ratingValue": "4.4",
"reviewCount": "3560"
}
}
</script>
اگر به نمونهها دقت کنید متوجه دو نکتهی خیلی مهم میشوید:
- اول، محتوای ساختارنیافتهی دو صفحه از وبسایت درقالب دادههای ساختاریافته درآمدند تا به الگوریتمهای گوگل کمک کنند تا بفهمند در هر صفحه دربارهی چهچیزهایی صحبت شده است.
- دوم، در دادههای ساختاریافته، انتیتیهای مختلف که در دادهی ساختارنیافته ذکر شده و ارتباطشان باهم برای الگوریتم ترجمه شده است.
گوگل چه محدودیتهایی برای درک انتیتیها داشت؟
مدل جستجوی گوگل تقریبا دو دهه است که بهآرامی تغییر میکند. این تغییر حرکت از مدل مبتنیبر کلمهی کلیدی بهسمت مدل مبتنیبر انتیتیها برای بازیابی اطلاعات از سراسر وب و نمایش آن در نتایج جستجو است.
بهعبارتدیگر، گوگل الگوریتمها و مدلی که آنها را آموزش میدهد، تغییر داده است.
برای درککردن تفاوت اساسی این دو مدل مثالی میزنیم:اگر از ctrl + f برای یافتن یک کلمه در یک متن استفاده کنید، از چیزی مشابه مدل بازیابی اطلاعات مبتنیبر کلمه کلیدی برای یافتن اطلاعات در فضای وب بهره بردهاید.
هر روز حجم عظیمی از داده در وب منتشر میشود. برای گوگل درک معنای هر کلمه، هر پاراگراف، هر مقاله و هر وبسایت بهسادگی امکانپذیر نیست. چون مدل بازیابی اطلاعات که مبتنیبر کلمه کلیدی است محدودیتی بنیادین دارد: این مدل نمیتواند محتواهایی را که با کلمه کلیدی و عبارت جستجوشده تطابق کامل و واضح ندارند، بازیابی کند.
راهحل گوگل این بود که الگوریتمهای جستجوی جدیدی را آموزش دهد. الگوریتمهایی که فقط بهدنبال کلمه کلیدی نبودند و میتوانستند ارتباط معنایی بین کلمات، عبارات و موضوعات (موجودیتها) را در یک محتوا با چیزی که کاربر جستجو میکند، تشخیص دهند.
برای نمونه، موجودیت آلبرت اینشتین که یک موجودیت انسانی است با موجودیتهای مفهومی فیزیک، نسبیت و جایزه نوبل مرتبط است.
موجودیتها ساختاری را فراهم میکنند که باعث میشود بار محاسباتی گوگل برای پردازش و یافتن اطلاعات از سراسر وب کاهش یابد و درعینحال الگوریتمها زمینه و معنای محتواها را بهتر درک کنند.
چالش گوگل این بود که با چه دادههایی (با کدام پایگاه داده) و بر چه اساسی الگوریتمهای جدید باید آموزش داده شوند. گوگل تصمیم گرفت فهم موجودیتها را به پیداکردن کلمات کلیدی اضافه کند و الگوریتمها را با دادههای ساختاریافته برپایهی موجودیتها و ارتباطات معناییشان باهم آموزش دهد.
از پردازش زبان طبیعی (NLP) برای شناسایی موجودیتهای درون محتوا استفاده کرد تا الگوریتمها بتوانند زبان طبیعی انسان را بفهمند و درک کنند.
برای آموزشدادن الگوریتمها نیز به پایگاه دانشی از دادههای ساختاریافته و مبتنیبر موجودیتها نیاز داشت.
گوگل پساز مدتها مطالعه و آزمونوخطا به این نتیجه رسید که باید پایگاه دانش مخصوص خودش را برای آموزش الگوریتمها و کمک به سیستمهایش بسازد:
Google’s Knowledge Graph آن پایگاه بود.
گراف یا نمودار دانش گوگل چیست؟
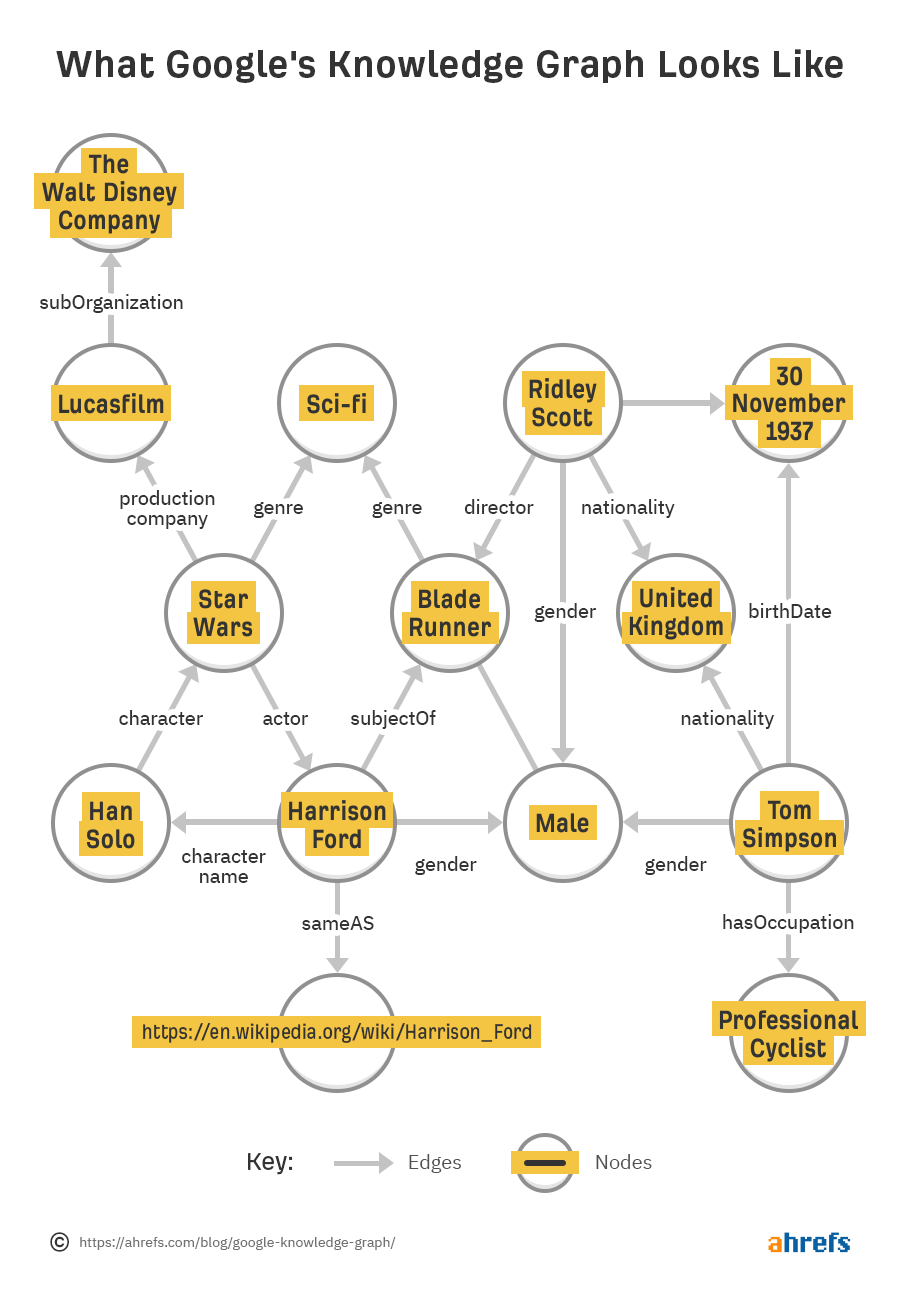
گوگل گراف دانش را اینطور تعریف کرده است:
نتایج جستجوی Google گاهیاوقات اطلاعاتی را نشان میدهد که از نمودار دانش ما، پایگاهی از دادهها دربارهی میلیاردها واقعیت درمورد افراد و مکانها و چیزها، بهدست میآید. نمودار دانش به ما امکان میدهد به سؤالاتی که از واقعیتهای جهان میپرسند، مانند ارتفاع برج ایفل چهقدر است؟ یا بازیهای المپیک تابستانی ۲۰۱۶ کجا برگزار شد؟، پاسخ دهیم.
کاری که نمودار دانش میکند این است که به سیستمهای ما امکان میدهد تا زمانیکه مفیدبودن ارائهی اطلاعات واقعی و عمومی تشخیص داده شد، آنها را پیدا کنند و در نتایج نمایش دهند.
در گراف دانش انتیتیها و ارتباطاتشان ذخیره میشود. این نمودار سیستمی است که اطلاعات مربوط به افراد، مکانها، سازمانها، رویدادها و سایر موجودیتها را بهروشی ساختاریافته تنظیم و بههم وصل میکند.
وقتی در مورد موضوعات خاص در گوگل جستجو میکنید، دادههای نمایشدادهشده درقالب پنلهای دانش و نتایج جستجوی غنیشده (ریچ اسنیپت) در جستجوی Google از گراف دانش استخراج میشود.
مهمترین ویژگیهای گراف دانش گوگل به شرح زیر است:
- اطلاعات موجودیتمحور: نمودار دانش بر انتیتیهای دنیای واقعی (مثلا یک سلبریتی، شهر، کتاب) و روابط بین آنها متمرکز شده است نه کلمات کلیدی.
- پنلهای دانش: براساس دادههای گراف دانش، یک پنل دانش که خلاصهای از مهمترین جزئیات دربارهی آن موضوع خاص را نشان میدهد، در نتایج جستجو ظاهر میشود. (برای نمونه، وقتی لئوناردو داوینچی را جستجو میکنید، پنلی که خلاصهای از بیوگرافی، دستاوردها و آثار هنریاش را دارد، ظاهر میشود).
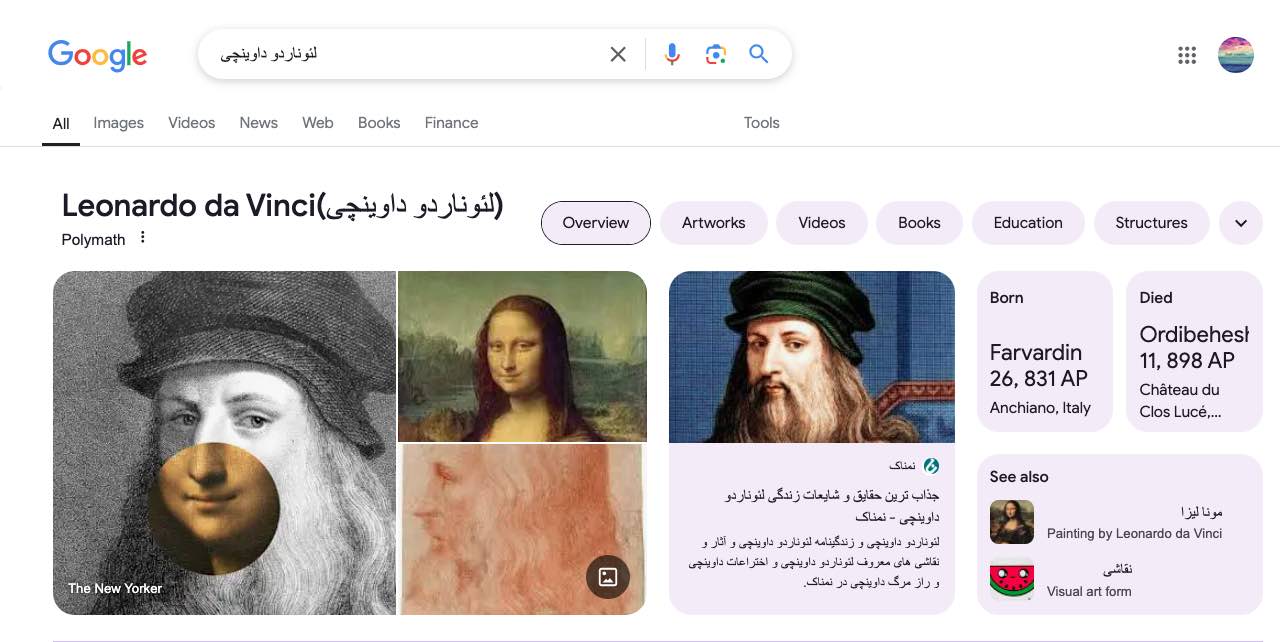
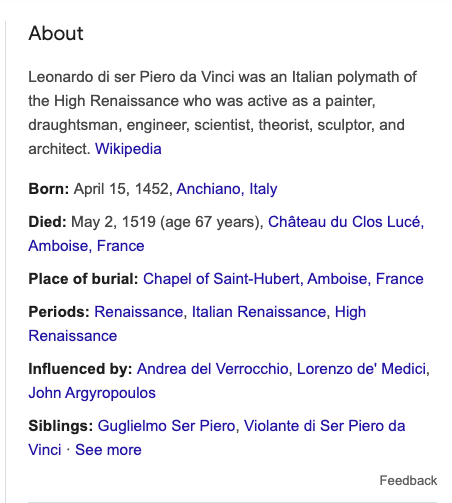
- موجودیتهای مرتبط: نمودار دانش موجودیتهای مختلف را براساس ارتباطی که باهم دارند، بههم وصل میکند. برای نمونه، لئوناردو داوینچی به نقاشی و مونالیزا وصل میشود.
- دادههای ساختاریافته: برای تضمین ذخیرهی اطلاعات دقیق و غنی، دادههای ساختاریافته از منابع مختلف، ازجمله Schema.org و Wikidata و پایگاههای دادهی عمومی، در گراف دانش باهم ادغام میشوند.
- جهانشمولی: در نمودار دانش گوگل دربارهی موضوعات متنوع در حوزههایی مانند علوم و فناوری، ورزش، تاریخ و فرهنگ، به چندین زبان داده ذخیره شده است.
گوگل گراف دانش را در سال ۲۰۱۲ معرفی کرد و مهمترین قدم را برای برداشتن محدودیت درک انتیتیها و معانی متنها برداشت و تمرکز بیشتر بر جستجوی معنایی (Google Semantic Search) را اعلام کرد.
الگوریتمهای گوگل به پایگاهی از دادههای ساختاریافته و موجودیتمحور که میتوانستند بخوانند و بفهمند دسترسی داشتند. دیگر راحتتر میتوانستند هم قصد و هدف کاربر از جستجوی یک عبارت یا کلمه را بهتر درک کنند و هم پاسخهای دقیقتر و مرتبطتر را به او نمایش دهند.
الگوریتم مرغ مگسخوار که در سال ۲۰۱۳ معرفی شد و تحولی عظیم در شیوهی پاسخدهی گوگل به سؤالات کاربران پدید آورد، به اطلاعات این پایگاه دسترسی دارد و هدفش این است که از عبارت جستجوشده به قصد کاربر پی ببرد و آنچه را که او واقعا بهدنبالش است پیدا کند.
با همهی این پیشرفتها، الگوریتمها همچنان برای فهم دقیق دادههای ساختارنیافته و یافتن موجودیتها و ارتباطات درون هر قطعه محتوا با مشکلات زیادی روبرو بودند.
مقولههای خاصی از موجودیتها بهراحتی تعریف میشوند، اما درک مفاهیم و ایدهها و تفاوتهای میان این دو دسته برای الگوریتمها بسیار سخت است.
برای آموزش مفاهیم انتزاعی و مبهم به الگوریتمها، یک صفحه یا چند محتوا کافی نیست. به مقالات و منابع متعدد و زمان زیادی نیاز است. چیزی که کار را سختتر و پیچیدهتر میکرد این بود که محتواهای فضای وب ساختارنیافته بودند و خواندن و درک آنها برای الگوریتمها کاری بسیار دشوار بود.
گوگل برای این هم راهحلی پیدا کرد.
Schema.org چیست؟
گوگل با همکاری Bing و یاهو برای انجام این کار Schema.org را ساخت. Schema.org مجموعه دستورالعملهایی را ارائه میدهد تا کارشناسان سئو و توسعهدهندگان وبسایت با گنجاندن آنها در هر محتوا (کدهای هر صفحه) به گوگل در درک محتوای یک صفحه کمک کنند.
Schema.org نقش مهمی در رساندن دادهها به نمودار دانش دارد. چون به کارشناسان سئو و وبمسترها کمک میکند تا محتوای وبسایت خود را به گونهای ساختار دهند که ماشین بتواند آنها را بخواند. این دادههای ساختاریافته به الگوریتمها امکان میدهد تا زمینه و معنای محتوا را درک کنند.
کارکردهای کدهای اسکیما به شرح زیر است:
- شناسایی و معرفی موجودیتها: با نشانهگذاری کدهای محتوا براساس دستورالعملهای اسکیما موجودیتهای موجود در یک صفحه (مانند محصولات، رویدادها، سازمانها یا افراد) برای الگوریتمها قابلشناسایی میشوند.
- ترسیم نقشهی ارتباطات: اسکیما فرادادههایی (متا دیتا) دربارهی روابط بین موجودیتها برای ماشین ترسیم میکند (مثلا، این نویسنده این کتاب را نوشته است یا این بازیگر در این فیلم بازی میکند).
- نتایج جستجوی غنی: محتوای نشانهگذاریشده با اسکیما در نتایج غنی یا پنلهای دانش، که از نمودار دانش استخراج میشود، نمایش داده میشود.
- ادغام دادهها و واقعیتها: نمودار دانش از دادههای ساختاریافته برای تأیید دادههایی که از صفحات مختلف وب و دیگر پایگاههای داده میگیرد، استفاده میکند.
همانطور که اشاره شد، گوگل تصمیم گرفته بود بر چیزها (موجودیتها) تمرکز کند، نه رشتهها. Schema.org مانع مهم دیگری را برای بهبود جستجوی معنای و عبور از مدل مبتنیبر کلمه کلیدی از میان برداشت.
گنجاندن کدهای اسکیما به هر صفحه از وبسایت آن را تبدیل میکند به مجموعهای از انتیتیها و روابط معنیدار برای الگوریتمها. گوگل دراینباره به کارشناسان سئو میگوید:
شما میتوانید با گنجاندن دادههای ساختاریافته در صفحه، سرنخهای واضح دربارهی معنای یک صفحه به گوگل بدهید. دادههای ساختاریافته قالبی استاندارد برای ارائهی اطلاعات دربارهی یک صفحه و طبقهبندی محتوای صفحه است. برای نمونه، در یک صفحهی دستور غذا با گنجاندن کدهای اسکیما دادههای اینطور طبقهبندی میشوند: مواد لازم، زمان و دمای پخت، کالری و … .
شما باید تمام ویژگیهای مربوط به یک موجودیت را به گوگل معرفی کنید تا برای ظاهرشدن در نتایج جستجو با نمایش بهینهتر (درقالب نتایج غنیشده و پنل دانش) درنظر گفته شوید. درکل، تعریف ویژگیهای توصیهشده احتمال ظاهرشدن اطلاعات وبسایت شما را در نتایج جستجوی بهینهتر افزایش میدهد. بااینحال، ارائهی ویژگیهای کمتر اما با اطلاعات کامل و دقیق، بهتر از ارائهی ویژگیها با دادههای ناقص، بد یا نادرست است.
میشود دربارهی اسکیما بیشتر صحبت کرد، اما کافی است این نکته را فراموش نکنید که اسکیما ابزاری فوقالعاده مهم برای کارشناسان سئو است تا محتوای وبسایت را کاملا برای موتورهای جستجو دسترسپذیر کنند.
گوگل در دو دهه سیستمی را که کاملا بر یافتن کلمات کلیدی متمرکز بود به سیستمی چندلایه تبدیل کرد که ازطریق گراف دانش و بررسی و ساختاردهی سیستماتیک به دادهها در سراسر وب معنای کلمات و متنها را درک میکند.
برای درک بهتر ارتباط گراف دانش و انتیتیها به این نمونه توجه کنید. در یک صفحه از وبسایتی، کتاب گتسبی بزرگ معرفی شده است.
کدهای اسکیمای این صفحه به این شکل است:
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Book",
"name": "The Great Gatsby",
"author": {
"@type": "Person",
"name": "F. Scott Fitzgerald"
},
"datePublished": "1925-04-10",
"genre": "Fiction"
}
</script>
الگوریتمها با خواندن این کدها میفهمند که محتوای صفحه دربارهی یک کتاب است که نام نویسنده، تاریخ انتشار و ژانر مشخصی هم دارد.
گراف دانش، این دادهها را همراه منابع دیگر (مانند ویکیپدیا، کتابخانهها) جمع میکند تا درک خود را از این کتاب و زمینهی آن بیشتر کند.
هنگامیکه کاربران برای کتاب گتسبی بزرگ جستجو میکنند، ترکیبی از این اطلاعات دربارهی آن را در پنل دانش به آنها نمایش میدهد.
در جدول زیر تفاوتهای اصلی گراف دانش و Schema.org آمده است:
| تفاوتهای گراف دانش و اسکیما | ||
| Schema.org | گراف دانش گوگل | |
| هدف | ارائهی قالب و کلمات استاندارد برای ساختاردادن به محتوای صفحات وب | سیستم مرکزی برای سازماندهی و اتصال موجودیتها |
| مخاطب | کارشناسان سئو و توسعهدهندگان وب | کاربران گوگل |
| خروجی | نتایج جستجوی غنی و دادههای قابلخواندن برای ماشین | ادغام اطلاعات و ساختن پنل دانش |
| منبع داده | محتوای نشانهگذاریشدهی وبسایتهای مختلف با کدهای اسکیما | Schema.org، پایگاه دادههای عمومی و دادههای خود گوگل |
چگونه محتوا را برای موجودیتها بهینه کنیم؟
گوگل در کمتر از ۱۰ سال از شناسایی و تعریف ۵۷۰ میلیون موجودیت و ۱۸ میلیارد واقعیت به ۸۰۰ میلیارد واقعیت و ۸ میلیارد موجودیت رسید. این نشان میدهد مدل مبتنیبر موجودیتها هر روز بهتر میشود چون الگوریتمهای گوگل مدام با اطلاعات و دادههای جدید آموزش میبینند و درک بهتری از زبان طبیعی انسان پیدا میکنند.
بر همین اساس است که کارشناسان سئو سایت باید وبسایت خود را برای موجودیتها و مدل جدید جستجوی گوگل کاملا بهینه کنند. برای این کار علاوهبر رعایت اصول سئو محتوا باید استراتژیهای دیگری را هم برای تولید محتوا دنبال کنند.
برای شروع بهتر است از ویکیپدیا بهعنوان راهنمای سئو موجودیتها کمک گرفت.
ساختار صفحات ویکیپدیا به این شکل است:
- عنوان
- بخش اصلی
- لینکهای رفع ابهام
- کارت اطلاعات (خلاصه حقایق کلیدی در مورد موجودیت)
- متن مقدمه
- فهرست مطالب
- محتوای اصلی
- ضمیمهها و مطالب پایانی
- منابع و یادداشتها
- لینکهای خارجی
- دستهها
مقالات ویکیپدیا معمولا با یک مقدمهی کوتاه شروع میشود که خلاصهای از مقاله است و بیشاز چهار پاراگراف نیست. مقدمه جذاب است و خواننده را تشویق میکند که مطلب را تاانتها بخواند.
جملهی اول و پاراگراف اول اهمیت ویژهای دارند. جملهی اول معرفی موجودیت توصیفشده در مقاله است. پاراگراف اول تعریف مفصلتری را بدون جزئیات زیاد ارائه میدهد.
ارزش لینکها بیشاز کمک به ناوبری است. آنها روابط معنایی بین مقالات ایجاد میکنند. علاوهبراین، متنهای لنگر (انکر تکست) منبعی غنی از انواع نام موجودیتهای مرتبط دیگر است.
بنابراین، برای تولید محتوا دربارهی هر موجودیت باید از ساختاری شبیهبه ساختار صفحات ویکیپدیا پیروی کرد. باید مشخص کرد که محتوا دربارهی کدام موجودیت است و ارتباط معناداری بین آن و دیگر موجودیتهای مرتبطش با لینکسازی داخلی برقرار کرد.
این کار سختی است و دیگر به تحقیق برای یافتن کلمات کلیدی خلاصه نمیشود. باید طوری محتوا را تهیه و به گوگل عرضه کرد که الگوریتمها و سیستم پردازش زبان طبیعی آن قادر باشد محتوای ساختارنیافته را بخوانند و موجودیتهای درونش را شناسایی کنند.
بهعبارتدیگر، یک مخاطب دیگر به فهرست مخاطبین محتوا اضافه شده است: کاربران، رباتهای گوگل و از این پس سیستم پردازش زبان طبیعی.
برای سئوی محتوا برای موجودیتها ابتدا باید قصد کاربران مختلف از جستجوی آن موجودیت را یافت.
۱. پوشش موضوعی کامل دربارهی یک موجودیت
قصد و هدف هر کاربر از جستجوی چیزی در گوگل براساس سابقهی جستجوهای قبلی او و زمینههای مرتبط دیگر تحلیل میشود. ممکن است دو نفر دربارهی یک موجودیت جستجو کنند، اما قصدشان از جستجو فرق کند و درنتیجه گوگل هم نتایج متفاوتی را به آنها نشان دهد.
اگر میخواهید محتوای وبسایت شما که دربارهی آن انتیتی است، به هر دو کاربر نمایش داده شود، در محتوا باید هر دو نوع قصد پوشش داده شده باشد. درآنصورت است که وبسایت شما کاندید بهتری برای رتبهآوردن در نتایج است.
بنابراین، اگر ممکن باشد که کاربران با چندین نوع قصد و هدف مختلف دربارهی موجودیتی در گوگل جستجو کنند، محتوای شما که دربارهی آن انتیتی است باید با درنظرگرفتن همهی آن قصدها و اهداف تولید شده باشد.
محتوای جامعوکامل درحقیقت محتوایی است که همهی موضوعات مرتبط به یک موجودیت را پوشش داده باشد.
چطور باید تمام قصدهای احتمالی از جستجوی یک انتیتی را یافت؟ از People Also Ask و People Search For و Autocomplete گوگل کمک بگیرید. سؤالات و مواردی که در آن بخشها نمایش داده میشود یا از نظر معنایی با موجودیت مرتبط است یا واژگان مشابهبه آن است یا موضوعات مرتبط دیگر را نشان میدهد.
محتواهای شما باید بیشترین تغییرات ممکن در قصد کاربران از جستجو دربارهی یک انتیتی خاص را پوشش دهند. یعنی هر موضوعی که شباهت واژگانی، معنایی یا کلیکی با انتیتی اصلی دارد، باید درنظر گرفته شود.
درکل، در تولید محتوا برای وبسایت، باید تمامی موجودیتهای مربوط به حوزهی تخصصی و هر نوع تغییر در قصد کاربران از جستجو دربارهی آنها را دراولویت قرار داد.
اگر قرار باشد براساس ساختار ویکیپدیا دربارهی یک موجودیت تولید محتوا کنید، باید براساس نوع موجودیت به تمامی سؤالات زیر در محتوا پاسخ دهید:
- این موجودیت چیست/کیست؟
- چه ویژگیهایی دارد؟ (هر بخش به مقالهای کاملا اختصاصیافته به آن موضوع لینک دارد.)
- چه چیزهایی دربارهی آن باید در نظر گرفته شود؟ (مخاطب هر کدام باید مشخص شود و تعاریف برای هر زیربخش مشخص شود.)
- مزایای آن چیست؟
- چه کاری انجام میدهد؟
- چگونه این کار را انجام میدهد؟
- چگونه آن را پیدا کنیم یا بخریم؟
- چهکسی میتواند با آن کار کند؟
- چهچیزهایی دیگری آن کار را انجام میدهند؟
- لینک برگشت به تمام دستهها و زیردستهها
۲. رفع هر نوع ابهام برای سیستم پردازش زبان طبیعی
هر کلمه، جمله و پاراگراف هنگام توضیح دربارهی یک موجودیت مهم است. نحوهی سازماندهی محتوا میتواند درک گوگل از محتوای شما را تغییر دهد.
برای نمونه، من در این محتوا کلمه کلیدی «سئو محتوا» را استفاده کردم، اما آیا گوگل آن کلمه کلیدی را همانطور که من میخواهم درک میکند؟
رفع ابهام دربارهی موجودیتها بسیار مهم است. چون زبان مبهم است و سیستم پردازش زبان طبیعی و الگوریتمها در فهم زبان ما انسانها مشکل دارند.
بنابراین باید از کلمات و عبارات و جملات برای گوگل رفع ابهام کنیم. برای سازماندهی به محتوایی با ساختار منظم، مشخص و شفاف دربارهی یک انتیتی اصلی و دیگر انتیتیهای مرتبط به آن میتوانید از روشهای زیر کمک بگیرید:
- Natural Language API: ابزار API زبان طبیعی Google Cloud ابزاری است که موجودیتهای یک محتوا را شناسایی و طبقهبندی میکند. اگر محتوایی را به این ابزار بدهید، به شما میگوید که سیستم پردازش زبان طبیعی گوگل این محتوای ساختارنیافته را چطور میخواند و میفهمد و انتیتیهای موجود در آن را درک میکند. این ابزار مشخص میکند که هر موجودیت برای سیستمها چهقدر برجسته جلوه میکند. البته، این ابزار دادههای تحلیلی دیگری را هم دربارهی محتوا از نگاه الگوریتمهای گوگل به شما میدهد. (در تصویر زیر، متن پیشفرض این ابزار بررسی شده است.)
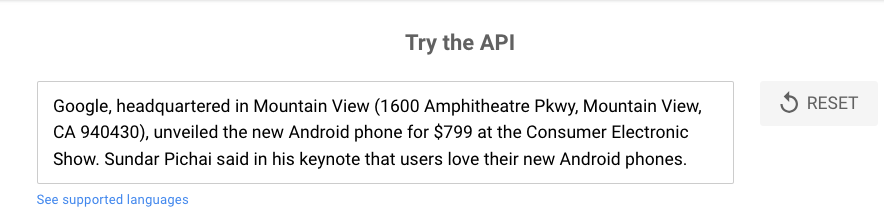
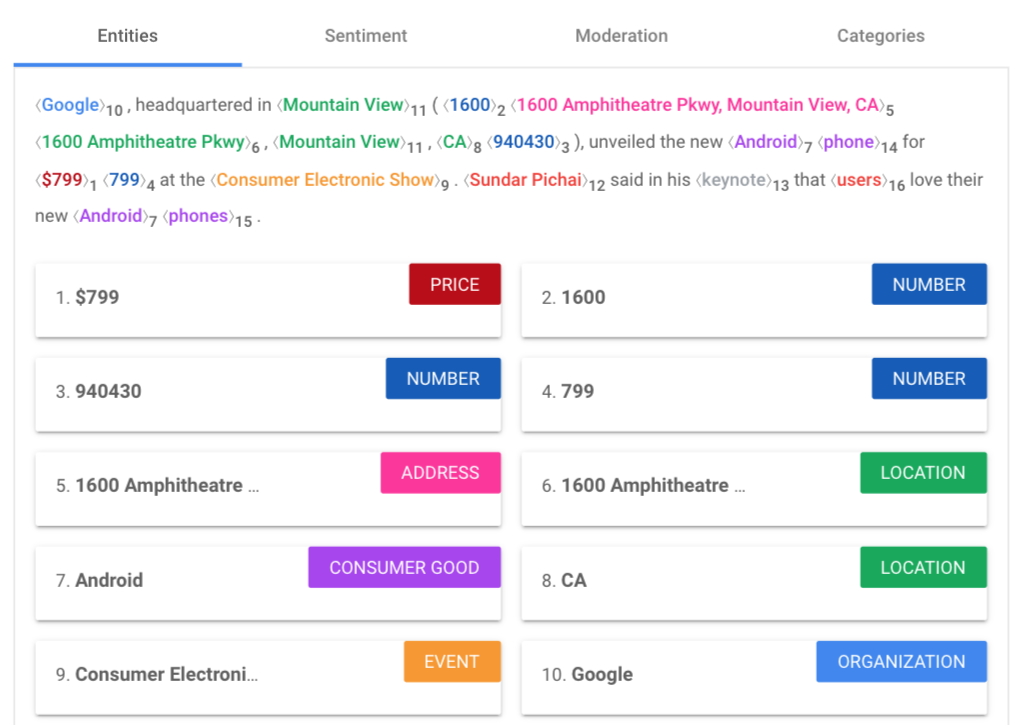
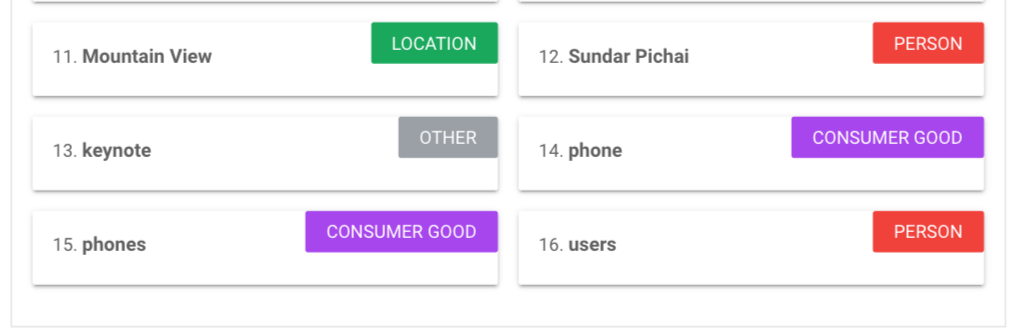
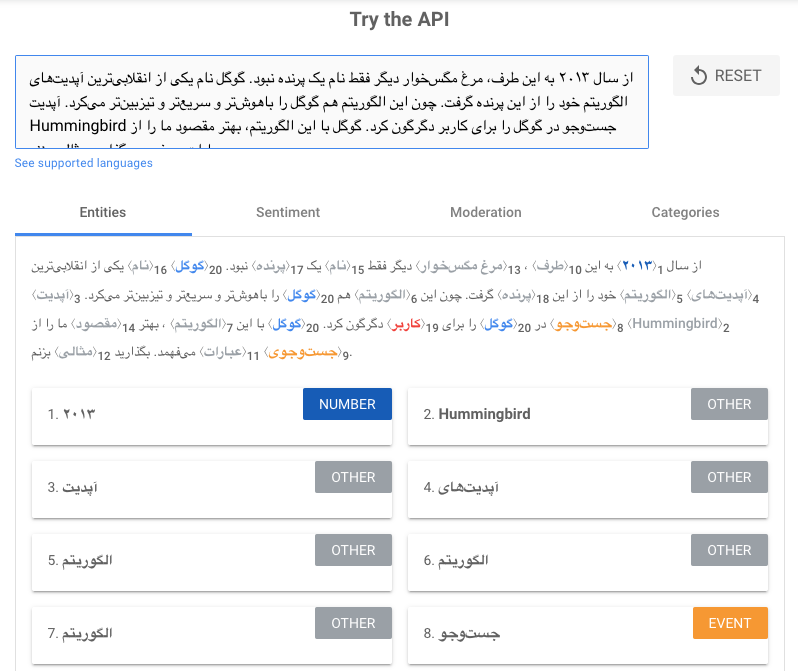
در تصاویر زیر نیز ارزیابی یک متن فارسی را میبینید.
- انسجام و هماهنگی در انکر تکستها و لینکسازیها: تمام لینکسازیها باید هدفمند باشد، یعنی به محتواهایی لینک داده شود که یکی از موضوعات مرتبط را توضیح داده است. علاوهبرآن، به شباهت زمینهای بین بخشی از محتوا که در آن لینکسازی میکنید و ارتباط موضوعی و معنایی تمام انکر تکستها با موجودیت اصلی توجه کنید.
- کدهای اسکیما: با گنجاندن کدهای اسکیما برای محتوا، شما موجودیتهای بلاگ وبسایت را به پایگاههای دانش پیوند میزنید. خوانندگان یک محتوا میتوانند با یک کلیک اطلاعات زمینهای یا مرتبط را بهدست آورند و بهراحتی به موجودیتهای مرتبط دسترسی پیدا کنند. توجه کنید که گوگل میخواهد سلسله مراتب محتوا را درک کند. هنگامیکه محتوا را با اسکیما بهینه میکنید، برای NER (Named Entity Recognition یا شناسایی موجودیت نامگذاریشده) نیز محتوا را بهینه میکنید. شناسایی موجودیت نامگذاریشده به معنی شناسایی موجودیت، استخراج موجودیت و تکهبندی موجودیت است.
۳. افزودن داده یا اطلاعی جدید به دادههای قبلی
کارشناسان سئو از ابزارهای سئو سایت برای بهینهسازی محتوای خود استفاده میکنند. البته، هر ابزار محدودیتهایی دارد. در بیشتر موارد، ابزارها فقط نتایج برتر SERP را جمعآوری و تحلیل میکنند و میانگینی تقریبی را برای تقلید پیشنهاد میدهند.
کارشناسان و مدیران سئو باید بهیاد داشته باشند که گوگل بهدنبال همان اطلاعات تکراری نیست. میتوانید کاری را که دیگران انجام میدهند کپی کنید، اما اطلاعات منحصربهفرد کلید تبدیلشدن به وبسایت معتبر است.
در اینجا نحوهی برخورد گوگل با محتوای جدید را ساده توصیف میکنیم: پساز اینکه مشخص شد محتوایی به یک موجودیت خاص اشاره دارد، ممکن است گوگل آن محتوا را بررسی کند تا شاید حقایق و دادههای جدیدی پیدا کند که با آن اطلاعات، مدخل پایگاه دانش موجودیت بهروز شود.
هرکسی که پایگاههای دانش، تشخیص موجودیت و خزشپذیری اطلاعات را بهبود بخشد، عشق گوگل را بهدست میآورد.
نکتهی مهم این است که تغییرات ایجادشده در پایگاه دانش را میشود ردیابی کرد و به محتوایی که منبعش بوده است، رسید.
اگر محتوایی منتشر میکنید که موضوعی را پوشش میدهد و در آن داده یا بینش جدیدی که نادر یا جدید است ارائه شده، گوگل میتواند شناسایی کند که محتوای شما آن اطلاعات منحصربهفرد را برای اولینبار به فضای وب وارد کرده و افزوده است. همین سبب میشود که وبسایت شما در حوزهی تخصصیاش به یک مرجع تبدیل شود.
این اعتبار از جنس اعتبار دامنه نیست بلکه به پوشش موضوعی وسیع و جامع دربارهی یک انتیتی مربوط میشود.
با رویکرد موجودیتمحور به سئو سایت، دیگر محدود به هدفگیری کلمات کلیدی با حجم جستجوی زیاد نیستید.
تمام کاری که باید انجام دهید این است که انتیتی اصلی را مشخص کنید و سپس میتوانید خودتان را جای کاربرانی که دربارهی آن جستجو میکنند بگذارید و قصد هر کدام را حدس بزنید.
مثالی میزنیم تا این فرآیند روشنتر شود. تصور کنید میخواهید یک فروشگاه اینترنتی لوازم ماهیگیری را سئو کنید و میخواهید برای موجودیت چوب ماهیگیری تولید محتوا کنید.
بروید سراغ ویکیپدیا و ببینید در مقالهی چوب ماهیگیری با مگس یا حشرهمصنوعی به چه موضوعات و مفاهیم (موجودیتها) مرتبط دیگری اشاره شده است. با بررسی آن مقاله به موجودیتهای زیر میرسید:
گونههای ماهی، تاریخچه، مبدا، توسعه، پیشرفتهای تکنولوژیکی، گسترش، روشهای ماهیگیری با مگس، ماهیگیری با مگس برای ماهی قزلآلا، تکنیکهای ماهیگیری با مگس، ماهیگیری در آب سرد، ماهیگیری مگس خشک قزلآلا، نایمفینگ برای قزلآلا، ماهیگیری آب ساکن، بازیکردن قزلآلا، رهاکردن قزلآلا، ماهیگیری با مگس آب شور، ابزار، مگسهای مصنوعی، حشرات مصنوعی.

حالا نوبت میرسد به تحقیق بیشتر و صدالبته خلاقیت در تولید محتوا. میتوانید بیشتر تحقیق کنید و از ابزارهای مختلف (ازجمله ابزارهای تحلیل رقبا) کمک بگیرید و موضوعات بیشتری را به آن فهرست اضافه کنید.
مثلا، برای موضوع «ماهی»، چندین موضوع اضافه کنید، ازجمله تکامل، آناتومی و فیزیولوژی، بیماریهای ماهی، حفاظت و اهمیت برای انسان. و بعد راهی برای ارتباط آن به ماهیگیری و چوب ماهیگیری پیدا کنید:
- آیا کسی آناتومی ماهی قزلآلا را به اثربخشی تکنیکهای خاص ماهیگیری مرتبط کرده است؟
- آیا یک وبسایت فروش لوازم ماهیگیری انواع تکنیکهای ماهیگیری، میلهها و طعمه را به تمام گونههای ماهی مرتبط کرده است؟
به این ترتیب، موضوعات خلاقانهتر و ارتباطات معنادارتری میان موجودیتهای مرتبط میتوانید پیدا کنید. این فرآیند را هنگام برنامهریزی برای تولید محتوا در ذهن داشته باشید.
فقط بازنشر نکنید. دادهای جدید یا بینش و ارتباطی معنادار و مرتبط و نوآورانه به دادههای گوگل اضافه کنید. بگذارید گوگل شما را همکار خود برای آموزشدادن به الگوریتمها و پایگاه دادهاش بداند.
جمعبندی و نتیجهگیری
کارشناسان و مدیران سئو سایت و کسانیکه سئو را آموزش میدهند، مدام میگویند که باید محتوای جامع و جدید تولید کرد. محتوایی که ارزشآفرین باشد و نیازهای مخاطب را برآورده کند.
اما راهحل و مسیری که برای تولید چنین محتوایی آموزش یا نشان میدهند، چندان درست نیست.
مدل جستجوی گوگل تغییر کرده است. گوگل از پردازش زبان طبیعی و ماشین لرنینگ بهره برده است تا موتور جستجویی شود که مثل یک انسان زبان کاربرانش را بفهمد. درنتیجهی آن تغییر، موتورهای جستجو بهدنبال کشف معنای جستجوها هستند نه کلماتی که جستجو میشود.
گوگل در برنامهریزی دقیقی موانع موجود در درک زبان طبیعی را شناسایی و با مطالعه و آزمونوخطا آنها را از سر راه برداشت.
گوگل سرمایهگذاری عظیمی برای تحقیق و ساخت پایگاه دانش (گراف دانش گوگل) و آموزش الگوریتمهایش کرده است تا این الگوریتمها هر روز بیشازپیش زبان انسان را بفهمند.
پایگاه دانش گوگل مخزن عظیمی از تمامی حقایق و موجودیتهای جهان خارج است. هر موجودیت یا حقیقت علمی که تاکنون دربارهی آن در فضای وب محتوایی منتشر شده در آن پایگاه ذخیره شده است.
دادهها در آن پایگاه ساختاریافته و براساس ارتباطات معنایی که باهم دارند، بههم وصل شدهاند. بنابراین، سیستمهای گوگل بهراحتی میتوانند آنها را بخوانند و دادهای را استخراج کنند.
برای راحتترشدن کار الگوریتمها گوگل مجموعهای از دستورالعمل و واژگان استاندارد، کدهای اسکیما، را برای کارشناسان سئو و توسعهدهندگان وبسایت تهیه کرد تا با کمک آن نسخهای ساختاریافته از محتواهای ساختارنیافته وبسایت دراختیار الگوریتمها و خزندگان قرار بگیرد.
کدهای اسکیما موجودیتهای بهکاررفته و ارتباط معنایی آنها را در محتوا درقالب کد به گوگل معرفی میکند.
درحقیقت، راهحل گوگل برای آموزشدادن زبان طبیعی انسان به سیستمهایش استفاده از موجودیتها بود: موجودیتها، ویژگیها، تمایزها و ارتباطی که باهم دارند جایگزین تشخیص مکانیکی کلمات کلیدی شد.
این تلاش گوگل هماهنگ است با تلاش برای دستیافتن به هدف بزرگتر این موتور جستجو که میخواهد به موتور جستجویی شخصیشده برای هر کاربر تبدیل شود.
سرمایهگذاریاش بر گوگل دیسکاور نشاندهندهی حرکت در مسیری کاملا متفاوت و تازه است. مسیری که به خلق تجربهای شخصیسازیشده برای هر کاربر و پیشبینی نیازها و سؤالاتش میرسد.
برای تعامل با هر کاربر به زبان خودش لازم است اول گوگل زبان طبیعی انسان را کاملا بیاموزد.
به همهی اینها باید این را هم افزود که نتایج گوگل تنها جایی نیست که محتواهای وبسایت رتبهبندی و نمایش داده میشود. موتورهای مولد مبتنیبر هوش مصنوعی مانند ChatGPT و Gemini هم برای پاسخدادن به سؤالات کاربران محتواهای وبسایتها را بررسی میکنند.
برای سئو محتوا و وبسایت بهگونهای که هم در موتور جستجوی گوگل و هم در گوگل دیسکاور و موتورهای مولد رتبه بیاورد و اعتبار کسب کند، باید موجودیتها را سئو کرد.
درست است که همچنان بعضی محتواها و وبسایتها با ترفندهای سئو کلاه خاکستری در نتایج گوگل رتبه میآورند، اما باور کنید رتبههایشان ماندگار نیست.
بنابراین، تنها راه درست و ماندگار برای سئو سایت و تولید محتوا، سئو با رویکرد موجودیتمحور است. کلمات کلیدی را فراموش کنید و برای موجودیتها و براساس ارتباطات معنادار میان موجودیتها تولید محتوا کنید.
راهنمای شما در این مسیر ویکیپدیا است. برای یافتن موجودیتها از این پایگاه داده کمک بگیرید. در تولید محتوا برای یک موجودیت به تمام موضوعات مرتبط با آن بپردازید.
یادتان باشد که سیستم پردازش زبان طبیعی گوگل هم مخاطب محتوای شما است. پس، باید همهی اشارهها و ارتباطات را واضح و روشن کنید.
درنهایت، خلاقیت و ارزشآفرینی را فراموش نکنید. گوگل به محتوایی علاقه دارد که دادهای جدید به این اقیانوس بیکران دادهها اضافه میکند.
پرسشهای متداول دربارهی سئو موجودیتمحور
۱. سئو انتیتیمحور چیست؟
سئوی مبتنیبر موجودیت رویکردی در بهینهسازی وبسایت برای موتورهای جستجو است که در آن بهجای تکیه بر کلمات کلیدی، بر مفهوم موجودیتها بهعنوان عنصر مرکزی محتوا تمرکز میشود.
۲. انتیتی (Entity) چیست؟
یک موجودیت ممکن است هر چیزی، یک شخص، مکان، سازمان، برند، مفهوم یا ایده، باشد. ویژگی موجودیت این است که منحصربهفرد است و قابلشناسایی و تمایز از دیگر موجودیتها. همچنین هر موجودیت را میشود واضح و کوتاه تعریف کرد.
۳. چه تفاوتی بین سئو موجودیتمحور و سئو کلمهکلیدیمحور وجود دارد؟
تفاوت سئو کلمهکلیدیمحور و سئو انتیتیمحور در این است که در اولی محتوا براساس کلمات کلیدی که کاربران جستجو میکنند تولید میشود و در دومی براساس درک مفاهیم و ارتباط بین موجودیتها. مثلا، بهجای تمرکز بر عبارت «خرید گوشی اپل»، موتور جستجو بهدنبال درک موجودیت «اپل» و رابطهی آن با «گوشی» و «خرید» است.
۴. چرا سئو انتیتی اهمیت دارد؟
سئو موجودیتها مهم است چون باعث میشود موتورهای جستجو بهتر مفهوم و قصد جستجوهای کاربران را درک کنند و در انتخاب نتایج جستجو دقیقتر و هدفمندتر باشند و نتایج جستجو براساس معنا و مفاهیم مرتبط با قصد و هدف کاربر نه فقط تطابقبا کلمهکلیدی به او ارائه شود.
۵. گوگل چگونه موجودیتها را شناسایی میکند؟
گوگل از پایگاه دانش خودش، گراف دانش، و دیگر پایگاههای دانش مانند ویکیپدیا، ویکیدیتا و الگوریتمهای هوش مصنوعی استفاده میکند تا مفاهیم و ارتباطات را شناسایی و سازماندهی کند.
۶. پایگاه دانش چیست؟
پایگاه دانش مخزن متمرکزی از اطلاعات ساختاریافته و ساختارنیافته است که برای دسترسی آسان، مدیریت و بازیابی دانش سازماندهی شده است. پایگاه داده برای ذخیره و مدیریتکردن دادهها، بینشها و راهحلها استفاده میشود و منبعی برای استخراج داده برای انسانها و ماشینها است.
۷. فرق داده ساختاریافته و ساختارنیافته در چیست؟
دادههای ساختاریافته دادههایی است که درقالبی ذخیره میشود که ماشینها بتوانند پردازششان کنند و آنها را بفهمند. این دادهها در قالبهای مشخص مانند جدول و نمودار یا فرمتهای JSON، XML و … تعریف میشوند. ویدئوها، پادکستها، تمامی محتواهای بلاگ وبسایتهای مختلف همه در دستهی دادههای ساختارنیافته قرار میگیرند که ماشینها نمیتوانند بخوانندشان.
۸. دادههای ساختاریافته چه نقشی در سئو انتیتی دارند؟
دادههای ساختاریافته به موتورهای جستجو کمک میکنند تا موجودیتها و روابط میان آنها را دقیقتر شناسایی و درک کنند.
۹. گراف دانش گوگل چیست؟
در گراف دانش انتیتیها و ارتباطاتشان ذخیره میشود. این نمودار سیستمی است که اطلاعات مربوط به افراد، مکانها، سازمانها، رویدادها و سایر موجودیتها را بهروشی ساختاریافته تنظیم و بههم وصل میکند.
۱۰. نقش Knowledge Graph در سئوی مبتنی بر موجودیت چیست؟
گوگل با استفاده از Knowledge Graph، اطلاعات دربارهی موجودیتها را سازماندهی و برای ارائهی نتایج دقیقتر استفاده میکند.
۱۱. Schema.org چیست؟
Schema.org مجموعه دستورالعملهایی را ارائه میدهد تا کارشناسان سئو و توسعهدهندگان وبسایت با گنجاندن آنها در کدهای هر صفحه به گوگل در درک محتوای یک صفحه کمک کنند.
۱۲. آیا سئو انتیتیمحور به معنای حذف کلمات کلیدی است؟
خیر. کلمات کلیدی همچنان مهماند، اما در سئو انتیتی، تمرکز بر معنای کلمات (قصد کاربر از جستجو) و ارتباطات مفهومی است.
۱۳. چگونه میتوان سئو انتیتیمحور را در وبسایت پیاده کرد؟
استفاده از دادههای ساختاریافته با استاندارد Schema.org و تولید محتوای جامع که همهی موضوعات مرتبط با موجودیت اصلی را پوشش دهد و برای سیستم پردازش زبان طبیعی گوگل مبهم نباشد.
۱۴. چگونه میتوان موجودیتهای مرتبط را شناسایی کرد؟
با استفاده از پایگاه دانش ویکیپدیا و بخشهای People Also Ask و People Search For و Autocomplete موتور جستجوی گوگل میشود موجودیتهای مرتبط را شناسایی را شناسایی کرد.
۱۵. آیا استفاده از لینکسازی در سئو انتیتیمحور متفاوت است؟
بله. لینکسازی باید به موضوعات مرتبط با موجودیت اشاره کند تا موتور جستجو ارتباطات را بهتر درک کند.
۱۶. آیا سئو مبتنی بر موجودیتها فقط برای موتورهای جستجو اهمیت دارد؟
خیر. سئو انتیتیمحور تجربه کاربر بهتری فراهم میکند زیرا اطلاعات دقیقتر و مرتبطتری به کاربران ارائه میشود.
۱۷. آیا سئو انتیتی محور روی رتبهبندی وبسایت تأثیر دارد؟
بله. وبسایتهایی که اطلاعات جامع و دقیق درباره انتیتیها ارائه میدهند، شانس بیشتری برای دیدهشدن در نتایج جستجو و نمایش در پنلهای دانش دارند.
۱۸. آیا همهی وبسایتها باید با رویکر موجودیت محور سئو شوند؟
بله، همهی وبسایتها باید با رویکر موجودیت محور سئو شوند مخصوصا وبسایتهایی که روی موضوعات خاص یا موجودیتهای منحصربهفرد تمرکز دارند.
۱۹. چه ابزارهایی برای تحلیل موجودیتها وجود دارد؟
Google Cloud Natural Language ابزار مفیدی است که برای استخراج موجودیتها از متن و اینکه الگوریتمها چطور متن ساختارنیافته را پردازش میکنند، کاربردی است.
۲۰. چگونه میشود موجودیتها را به گراف دانش گوگل اضافه کرد؟
با استفاده از دادههای ساختاریافته Schema.org ممکن است موجودیتها را به گراف دانش گوگل اضافه کرد.
۲۱. آیا محتواهای بصری (تصاویر و ویدئوها) در سئو انتیتی مهم است؟
بله. تصاویر و ویدئوهایی که اطلاعات مرتبط با موجودیتها در آنها ارائه شده است مانند محتواهای متنی مهماند.
۲۲. آیا هوش مصنوعی نقش مهمی در سئو مبتنی بر انتیتی دارد؟
بله. هوش مصنوعی و یادگیری ماشین در پردازش زبان طبیعی و تحلیل متن، شناسایی موجودیتها و ارتباطات آنها نقش کلیدی دارند.
۲۳. نقش محتوا در سئو انتیتی چیست؟
محتوا باید جامع، دقیق و مرتبط با موجودیت باشد. تولید محتوای ساختارمند و شفاف برای موجودیتها و ارتباطاتشان بایکدیگر در سئو موجودیتمحور نقش اساسی دارد.
۲۴. چگونه سئو انتیتیمحور آیندهی موتورهای جستجو را تغییر میدهد؟
موتورهای جستجو این هدف را دارند که بر زبان طبیعی انسان مسلط شوند تا بتوانند نیازها و سؤالات کاربران را پیشبینی کنند و به آنها دقیقترین و مرتبطترین پاسخها را بدهند.

کمپ آموزش جامع سئو تخصصی
آموزش سئو
همواره یکی از مشکلاتی که طراحان سایت و شرکت ها با آن دست و پنجه نرم میکنند فروش و بازدید کم سایتشان است. یکی از دلایل اصلی دیده شدن سایتها و فروش بالای آن بهبود رتبه سایت در گوگل است که به این کار سئو گویند. و موفقیت هرکسی در کسب و کار اینترنتی، وابسته به دانش سئو و بهینه سازی وب سایت است.
همواره همه موسسات و شرکت ها ، در عصر امروزی به وب سایتی برای معرفی خدمات و محصولات خود نیاز دارند . که توسط طراحان سایت و برنامه نویسان این عمل انجام می شود. اما این پایان کار نیست . این خدمات و محصولات برای دیده شدن و فروش باید در گوگل و سایر موتور های جستجو دیده شوند که انجام این کار به عهده سئو است .
ادامه...







