از قدیم گفته اند “یک تصویر از هزاران جمله گویاتر است.”
در دنیای امروز، روزانه داده های بسیار زیادی تولید می شود. تجزیه و تحلیل این داده ها، به خصوص اگر داده ها خام باشند، ممکن است بسیار دشوار به نظر برسد. این جاست که بصری سازی داده ها یا Data visualization وارد صحنه می شود تا آنالیز داده ها را برای ما آسان و قابل درک کند. داده های بصری سازی شده، نمایش تصویری خوب و سازمان یافته ای از داده ها را به ما ارائه می دهد که درک، مشاهده و تجزیه و تحلیل آن را آسان تر می کند. بصری سازی داده ها در پایتون شاید یکی از پرکاربردترین ویژگی های زبان برنامه نویسی پایتون، مخصوصا در حوزه آنالیز داده است.
در این مقاله از مجموعه مقالات آموزش پایتون، به نحوه بصری سازی داده ها با استفاده از پایتون می پردازیم.
آنچه در این نوشته خواهیم داشت
بصری سازی داده (Data visualization) در پایتون
بصری سازی داده ها، تلاش برای درک داده ها با تبدیل آن ها به شکل قابل تجسم است تا الگوها، روندها و همبستگی هایی که در حالت عادی قابل شناسایی نیستند، آشکار شوند. به بیان دیگر، بصری سازی داده ها زمینه ای در تجزیه و تحلیل داده ها است که با نمایش بصری داده ها سروکار دارد. این روش، داده ها را به صورت گرافیکی ترسیم می کند و روشی مؤثر برای استنتاج از داده ها است.
با استفاده از بصری سازی داده ها، می توانیم خلاصه ای بصری از داده های خود به دست آوریم. ذهن انسان برای پردازش و درک داده ها با تصاویر، نقشه ها و نمودارها، راحت تر ارتباط برقرار می کند. زمانی که مجموعه بزرگی داریم، دیدن تمام داده ها غیرممکن است، چه برسد به پردازش و درک این داده ها به صورت دستی.
بیشتر بخوانید : “کلان داده چیست؟ (به همراه معرفی کتابخانه های کاربردی تحلیل داده)“
شاید بپرسید چرا برای بصری سازی داده ها از پایتون استفاده می کنیم؟
به این دلیل که زبان پایتون کتابخانه های رسم متنوعی را با ویژگی های مختلف برای ایجاد نمودارهای قابل فهم، جذاب و با قابلیت سفارشی سازی برای ارائه داده ها به ساده ترین و مؤثرترین روش ارائه می دهد.
کتابخانه های بصری سازی در پایتون
پایتون، کتابخانه های مختلفی را ارائه می دهد که دارای ویژگی های متفاوتی برای بصری سازی داده ها هستند. تمام این کتابخانه ها دارای ویژگی های مختلفی هستند و می توانند انواع مختلفی از نمودارها را پشتیبانی کنند. در این مقاله، چهار مورد از پر استفاده ترین این کتابخانه ها را معرفی خواهیم کرد.
بیشتر بخوانید : “۱۵ کتابخانه پایتون که باید بیاموزید! (راهنمای جامع برنامه نویسان پایتون)“
Matplotlib
Matplotlib یک کتابخانه بصری سازی داده سطح پایین و با کاربری آسان است که بر روی آرایه های NumPy ساخته شده است که توسط جان هانتر در سال ۲۰۰۲ معرفی شد. این کتابخانه شامل نمودارهای دو بعدی مختلفی مانند نمودار پراکندگی، نمودار خطی، هیستوگرام و غیره است. Matplotlib انعطاف پذیری زیادی را فراهم می کند.
Seaborn
Seaborn یک کتابخانه بصری سازی داده پایتون بر اساس Matplotlib است. این کتابخانه یک رابط کاربری سطح بالا برای ایجاد نمودارهای جذاب فراهم می کند.Seaborn چیزهای زیادی برای ارائه دارد. تفاوت کتابخانه Seaborn با Matplotlib این است که در Seaborn میتوانید نمودارها را در یک خط ایجاد کنید که ممکن است برای رسم همین نمودار در Matplotlib به دهها خط کد نیاز باشد. یکی دیگر از نقاط قوت این کتابخانه، سبک های طراحی زیبا و پالت های رنگی متنوع را برای ایجاد نمودارهای جذاب است.
Bokeh
Bokeh عمدتاً به دلیل بصری سازی نمودارها به روش تعاملی، مشهور است. نموادارهای رسم شده با Bokeh، با استفاده از HTML و جاوا اسکریپت ارائه می شود که آن را به ابزاری قدرتمند برای ایجاد پروژه ها، نمودارهای سفارشی و برنامه های کاربردی مبتنی بر طراحی وب تبدیل می کند. کتابخانه Bokehهمچنین از جریان داده های آنی (Real-time) پشتیبانی می کند. بوکه سه رابط با سطوح مختلف کنترل را برای انواع مختلف کاربر ارائه می دهد. بالاترین سطح برای ایجاد سریع نمودار است که شامل روش هایی برای ایجاد نمودارهای رایج مانند نمودارهای میله ای، نمودارهای جعبه ای و هیستوگرام است. سطح میانی همان ویژگی Matplotlib را دارد و به شما امکان میدهد بلوکهای اصلی هر نمودار را کنترل کنید (مثلاً نقاط در یک نمودار پراکنده).
پایین ترین سطح برای توسعه دهندگان و مهندسان نرم افزار است و از شما می خواهد که هر عنصر نمودار را تعریف کنید.
Plotly
plotly.py یک کتابخانه بصری سازی تعاملی، متن باز، سطح بالا و مبتنی بر مرورگر(مانند bokeh) است. این کتابخانه دارای مجموعه ای شامل نمودارهای علمی، نمودارهای سه بعدی، نمودارهای آماری، نمودارهای مالی و غیره است. plotly دارای قابلیتهای ابزار شناور است که به ما امکان میدهد هر گونه نقاط پرت یا ناهنجاری را در داده ها تشخیص دهیم.
برای آنالیز داده ها از کدام روش بصری سازی استفاده کنیم؟
برای استخراج اطلاعات مورد نیاز از تصاویر و نمودارها، باید سعی کنیم که بر اساس نوع داده ها از نمایش صحیح استفاده کنیم. در زیر مجموعه ای از پرکاربردترین نمایش ها و نحوه استفاده از آن ها را معرفی خواهیم کرد.
نمودار میله ای (Bar chart)
نمودار میله ای زمانی استفاده می شود که بخواهیم مقادیر یک متریک را در زیر گروه های مختلف، با هم مقایسه کنیم. نمودار میله ای را می توان با استفاده از تابع ()bar ایجاد کرد. در تکه کد زیر نمونه ای از ایجاد نمودار میله ای آورده شده است.
#Creating the dataset
df = sns.load_dataset('DataSetName')
df=df.groupby('who')['fare'].sum().to_frame().reset_index()
#Creating the bar chart
plt.barh(df['who'],df['fare'],color = ['#F0F8FF','#E6E6FA','#B0E0E6'])
#Adding the aesthetics
plt.title('Chart title')
plt.xlabel('X axis title')
plt.ylabel('Y axis title')
#Show the plot
plt.show()
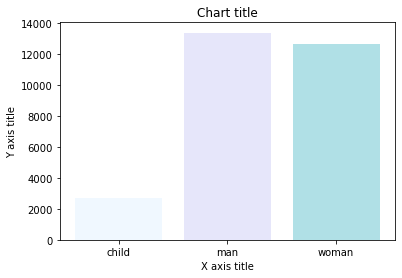
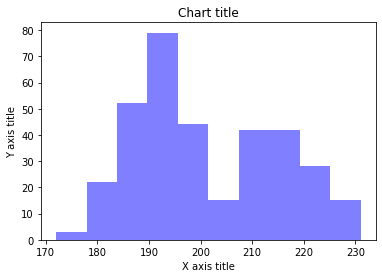
نمودار هیستوگرام
هیستوگرام برای نمایش داده ها در قالب گروه استفاده می شود. این نمودار، یک نوع نمودار میله ای است که در آن محور X محدوده bin را نشان می دهد در حالی که محور Y اطلاعاتی در مورد فرکانس می دهد. برای ایجاد مودار هیستوگرام از تابع ()hist استفاده می شود وبا ارسال دادههای طبقهبندی شده، به طور خودکار فرکانس آن داده را محاسبه میکند.
#Creating the dataset
penguins = sns.load_dataset("penguins")
#Creating the column histogram
ax = plt.gca()
ax.hist(penguins['flipper_length_mm'], color='blue',alpha=0.5, bins=10)
#Adding the aesthetics
plt.title('Chart title')
plt.xlabel('X axis title')
plt.ylabel('Y axis title')
#Show the plot
plt.show()
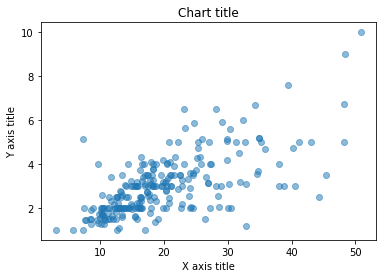
نمودار پراکندگی
از نمودارهای پراکندگی برای شناسایی روابط بین دو متغیر استفاده می شود.
#Creating the dataset
df = sns.load_dataset("tips")
#Creating the scatter plot
plt.scatter(df['total_bill'],df['tip'],alpha=0.5 )
#Adding the aesthetics
plt.title('Chart title')
plt.xlabel('X axis title')
plt.ylabel('Y axis title')
#Show the plot
plt.show()
نمودار خطی
نمودار خطی برای نمایش پیوسته نقاط داده، استفاده می شود. زمانی که میخواهیم روند تغییر یک متغیر را در طول زمان درک کنیم، میتوانیم از این نمودار استفاده کنیم.
#Creating the dataset
df = sns.load_dataset("iris")
df=df.groupby('sepal_length')['sepal_width'].sum().to_frame().reset_index()
#Creating the line chart
plt.plot(df['sepal_length'], df['sepal_width'])
#Adding the aesthetics
plt.title('Chart title')
plt.xlabel('X axis title')
plt.ylabel('Y axis title')
#Show the plot
plt.show()
نمودار دایره ای
از نمودار دایره ای برای شناسایی نسبت های اجزای مختلف در یک کل معین استفاده می شود.
#Creating the dataset
cars = ['AUDI', 'BMW', 'NISSAN',
'TESLA', 'HYUNDAI', 'HONDA']
data = [20, 15, 15, 14, 16, 20]
#Creating the pie chart
plt.pie(data, labels = cars,colors = ['#F0F8FF','#E6E6FA','#B0E0E6','#7B68EE','#483D8B'])
#Adding the aesthetics
plt.title('Chart title')
#Show the plot
plt.show()
نمودار محیطی
نمودار محیطی برای ردیابی تغییرات در طول زمان برای یک یا چند گروه استفاده می شود. زمانی که بخواهیم تغییرات را در طول زمان برای بیش از ۱ گروه ثبت کنیم، نمودارهای محیطی نسبت به نمودارهای خطی ترجیح داده می شوند.
#Reading the dataset
x=range(1,6)
y=[ [1,4,6,8,9], [2,2,7,10,12], [2,8,5,10,6] ]
#Creating the area chart
ax = plt.gca()
ax.stackplot(x, y, labels=['A','B','C'],alpha=0.5)
#Adding the aesthetics
plt.legend(loc='upper left')
plt.title('Chart title')
plt.xlabel('X axis title')
plt.ylabel('Y axis title')
#Show the plot
plt.show()
جمع بندی
در این مقاله، راهنمای کامل بصری سازی دادهها در پایتون را ارائه دادیم. همان طور که در این مقاله مطالعه کردید، برای بصری سازی داده در پایتون، مجموعهای از کتابخانههای مختلف وجود دارد که میتوان با شناخت موارد استفاده و نیاز خود، بهترین را انتخاب کرد. همانطور که می دانید، زبان برنامه نویسی پایتون با قدرت بصری سازی داده ها یا Data visualization، می تواند به شما کمک کند تا مجموعه داده های بزرگ و پیچیده را تحلیل و مدیریت کنید.
برای تهیه این مقاله از منابع زیر استفاده شده است:

دوره تخصصی یادگیری ماشین
در یک دوره آموزشی متخصص یادگیری ماشین شوید.
از یادگیری ماشین می توان در صنایع مختلف با اهداف مختلف استفاده کرد. ماشین لرنینگ باعث افزایش بهره وری در صنایع می شود، به بازاریابی محصول کمک کرده و پیش بینی دقیق فروش را ساده تر می کند. پیش بینی های دقیق پزشکی و تشخیص ها را تسهیل می کند. دقت در قوانین و مدل های مالی را بهبود می بخشد. به سیستم های توصیه گر، الگوریتم های فرا ابتکاری و حرکت ربات ها کمک خواهد کرد. در بحث فروش میتواند محصولات مناسب تری را به مشتری پیشنهاد دهد( با کمک به تقسیم بندی بهتر و پیش بینی دقیق طول عمر محصولات ) و ...
استفاده از سیستم های ماشین لرنینگ می تواند تا حد زیادی حجم کاری ما را کاهش دهد. به خصوص کارهایی که نیاز به آنالیز حجم عظیمی از داده و تصمیم گیری بر اساس این داده ها را دارد بسیار تسهیل می کند. سیستم های مبتنی بر ماشین لرنینگ ظرفیت انجام کار صد نفر را همزمان دارد و تنها به کمک ماشین ها می توان بدون صرف وقت و انرژی زیاد، کارهای سنگین را انجام داده و در عین حال پول و درآمد بیشتری کسب کرد. ماشین لرنینگ با خودکارسازی فرایندها و صرفه جویی در زمان، به ما کمک می کند تا بتوانیم زمان و انرژی خود را بر تصمیم گیری های پیچیده تری متمرکز کنیم.
ادامه...