



سوگیری الگوریتمهای شبکههای اجتماعی (social media algorithm bias) یعنی چه؟ مگر میشود الگوریتم سوگیری داشته باشد و پیشداوری کند؟ اصلا، چرا این موضوع مهم است؟
بسیاری از ما اخبار را از سوشال مدیا دنبال میکنیم. چیزهای مختلفی در پستها میبینیم. اتفاق افتاده است که خبر فوت بازیگر یا شخص مهمی در شبکههای اجتماعی پخش شده است. کاربران و اکانتهایی با دنبالکنندگان چندین هزارتایی هم آن خبر دروغ را منتشر کردند. اما چند ساعت نگذشته و آن شایعه تکذیب شده است.
اگر یادتان باشد وقتی واکسیناسیون کرونا در ایران شروع شد، در شبکههای اجتماعی حرفهای ضدونقیضی دربارهی آن زده شد. عدهای مخالف بودند و دلایلی هم داشتند. جالب بود که پستهایی با ادعاهای غیرواقعی و خطرناک دربارهی واکسن دست به دست میشد و لایک و کامنت میگرفت. بودند افرادی که در آن دوران فقط برای جلب نظر کاربران و دیده شدن ادعاهایی بسیار مضر برای سلامت عمومی منتشر کردند.
مطمئن هستم که شما هم نمونههایی را از جریانهای خطرناکی که در شبکههای اجتماعی راه افتاده است، به یاد دارید. وقتی برای چک کردن هر چیزی به اولین جایی که سر میزنیم، سوشال مدیاست؛ چه بخواهیم چه نخواهیم قضاوت و رفتار ما تحت تاثیر آن قرار میگیرد. متاسفانه، گاهی آن تاثیر چنان زیاد و شدید است که تبعات وحشتناکی برای افراد و جوامع دارد.
سوال مهم این است که چه باید کرد؟ اول باید دید ریشهی این مشکل کجاست و چه چیزهایی سبب میشود تا بعضی پستها و محتواها بیشتر دیده شوند و بعضیها کمتر؟ بعد باید دید چه راهحلهایی وجود دارد تا از اثرات سوء و مخرب شبکههای اجتماعی بر رفتار و واکنشهای کاربران به موضوعی مشخص جلوگیری کرد؟
این محتوا به آن سوالات پاسخ میدهد.
آنچه در این نوشته خواهیم داشت
سوگیری الگوریتمهای شبکههای اجتماعی
هوش مصنوعی غیرممکنهای زیادی را ممکن کرده است. با استفاده از هوش مصنوعی و ماشین لرنینگ یا یادگیری ماشین میشود به ماشینها (کامپیوترها و نرمافزارها) آموزش داد تا کارهایی را یاد بگیرند و انجام دهند. کاربردهای هوش مصنوعی و ماشین لرنینگ در حوزههای گوناگون صنعت و تکنولوژی تغییراتی بنیادین در شیوهی کار و زندگی انسانها ایجاد کرده است.
بعضی کاربردها یا شاید بهتر است بگویم نتایج بهکارگیری ماشین لرنینگ در حوزههای مختلف برای همهی ما بسیار مشهود است. مانند ChatGPT که از دستاوردهای معروف هوش مصنوعی است. رباتهای هوشمند و سخنگو هم حاصل پیشرفتها در ماشین لرنینگ و رشتهای بسیار تخصصی به نام پردازش زبان طبیعی هستند.
هوش مصنوعی و ماشین لرنینگ کاربردهای دیگری هم دارند که ما متوجه آنها نیستیم. اما آن کاربردها در زندگی تک تک ما تاثیرگذارند. شرکتهای توسعهدهنده شبکههای اجتماعی، هوش مصنوعی و ماشین لرنینگ را به خدمت گرفتند تا حجم عظیم محتوای تولید شده در این شبکهها را برای کاربران سامان دهند.
الگوریتمهای شبکههای اجتماعی ساخته شدند تا با استفاده از واکنشهایی که هر کاربر در شبکههای اجتماعی دارد، آن کاربر را بشناسند و پستها و محتواهایی (ازجمله محتواهای تبلیغاتی و اسپانسردار) را در فید (News Feed) به او نشان دهند که میدانند او میپسندد و به آنها علاقه دارد. پس، مشکلی وجود ندارد و الگوریتمها چیزهایی را که کاربران میخواهند به آنها نشان میدهند.
متاسفانه، مشکلی وجود دارد و موضوع به این سادگی نیست.
سوگیری زبانی الگوریتمها
الگوریتمها را انسانها آموزش میدهند، درست مانند یک بچه. چه میشود اگر بچهای در محیطی رشد کند که فقط سفیدپوستان را دیده باشد یا فقط سیاهپوستان را؟ یا چه میشود اگر بچه در محیطی بزرگ شده باشد که فقط در آن مدیرها یا معلمهای مرد وجود داشتهاند؟ آن بچه فکر میکند دنیا همین است و اگر از او دربارهی رنگینپوستان سوال شود، او جوابی ندارد. چون اساسا نمیداند در جهان نژادهای دیگری هم وجود دارند.
تحقیقات مختلفی نشان داده است که الگوریتمها سوگیری و پیشداوری خواهند کرد اگر با سوگیری و پیشداوری آموزش دیده باشند و فقط دادهها و اطلاعات مشخص و جهتداری به آنها داده شده باشد. پس، وقتی چیزی در دایرهی لغات الگوریتمها وجود نداشته باشد، آن را نمیبینند. البته، مشکل سوگیری زبانی الگوریتمها فقط این نیست.

شبکههای اجتماعی از الگوریتمها برای جلوگیری از انتشار محتواهای توهینآمیز، تروریستی و حمله و تخریب به یک شخص یا گروه نیز استفاده میکنند. یعنی الگوریتمها آموزش دیدهاند تا اگر در محتوایی بعضی کلمات وجود داشته باشد، آن را حذف کنند. اما مشکل اینجاست که بعضی کلمات و عبارات ممکن است در متنی به یک معنی استفاده شود که توهینآمیز است و در متن دیگری طوری استفاده شده باشد که توهینآمیز نیست. پس، معنی کلمات و عبارات با توجه به بافت کلام (context) تغییر میکنند. علاوه بر آن، بعضی کلمات برای گروهی از افراد و جوامع توهینآمیز تلقی نمیشوند.
پس، اگر الگوریتم با زبان انگلیسی استاندارد آموزش دیده باشد و از دادههای این زبان استفاده کند، انگلیسی آفریقای جنوبی (SAE) یا انگلیسی بومی آفریقایی-آمریکایی (AAE) را نمیفهمد. پس، ممکن است محتوایی را به اشتباه توهینآمیز یا مضر تشخیص دهد و حذف کند. در نتیجه، ممکن است صدای بعضی از گروهها و جمعیتهای قومی یا نژادی در شبکههای اجتماعی به اشتباه و ناعادلانه کم یا حتی خفه شود.
سوگیریهای اجتماعی و شناختی در نتیجهی بهکارگیری الگوریتمها در شبکههای اجتماعی
موتورهای جستجو هم مانند سوشال مدیا از الگوریتمها برای سامان دادن به محتواهای فضای وب استفاده میکنند. برای این الگوریتمها نیز توجه و تعامل کاربران به یک محتوا یا پست یا حساب کاربری بسیار مهم است. یعنی هر چه کاربران بیشتری به موضوعی واکنش نشان دهند یا به پستهای کاربر مشخصی توجه کنند، الگوریتمها آن موضوع، محتوا و کاربر را بیشتر نشان یا پیشنهاد میدهند. دلیل هم این است که آن محتوا و کاربر محبوب و پرطرفدارند.
سوال مهمی که پیش میآید این است که موضوعات، محتواها و دیدگاههای کمطرفدارتر در فضای وب چه میشوند؟ آیا این باعث نمیشود که نظرات یا افرادی سانسور شوند؟ از آنجایی که محبوبیت دلیلی بر درستی، صحت یا اعتبار یک موضوع یا شخص نیست، آیا این سبب نمیشود که محتواهای بیکیفیت، هیجانی و بیپایه و اساس و نامعتبر در فضای وب به سرعت بچرخد و نظرات مردم را دربارهی موضوعی تحت تاثیر قرار دهد؟ آیا همین باعث نمیشود که نظرات و دیدگاههای مخالف با جریان اکثریت ناشنیده بماند؟
بعضی تحقیقات نشان داده است که پاسخ سوالات بالا مثبت است. همین ویژگی الگوریتمها ممکن است به سوگیریهای شناختی و اجتماعی مختلفی در کاربران در مواجه با موضوعات مختلف سیاسی، اقتصادی، اجتماعی، فرهنگی، اعتقادی و حتی بهداشتی بینجامد.
رایجترین سوگیری های اجتماعی و شناختی در شبکههای اجتماعی
مهمترین و شایعترین سوگیریهای اجتماعی و شناختی که فیلتر شدن اطلاعات به وسیلهی الگوریتمها در فضای مجازی سبب میشود، عبارت است از: اثر حقیقت واهی، سوگیری تأیید، سوگیری مرجعیت، اثر اجماع کاذب و تعصب درون گروهی. (چون سوگیری تعصب درون گروهی از نامش معلوم و مشخص است، دربارهی آن توضیح بیشتری نمیدهم.)
- اثر حقیقت واهی: تکرار مدام یک مطلب سبب میشود تا بعضی به این باور برسند که آن درست و حقیقت است.
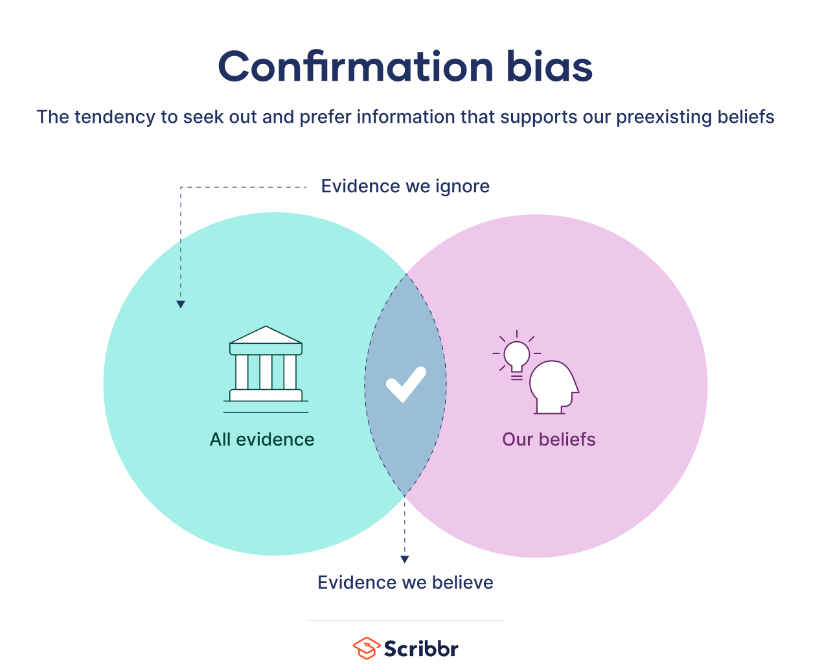
- سوگیری تایید: بعضی فقط اطلاعات و مطالبی را میبینند و میخوانند که با اعتقادات و باورهای آنها سازگار است.

- سوگیری مرجعیت: اگر دانشمند، سیاستمدار یا انسان مشهوری (با فالوئرهای زیاد) چیزی را بگوید، عدهای فکر میکنند حتما درست است و حقیقت دارد.
- اثر اجماع کاذب شبیه به همین سوگیری است. با این تفاوت که در اثر اجماع کاذب عدهای چیزی را درست میدانند که «همه» فکر میکنند درست است. برای مثال، چون پستی چندین هزار لایک خورده یا ویدئویی میلیونها بار مشاهده شده است، حتما معتبر و درست و قابل اعتماد است.


جمعبندی و نتیجهگیری
۱. قطعا هوش مصنوعی و ماشین لرنینگ معایبی دارند و نیمهای تاریک (در نیمه تاریک هوش مصنوعی و ماشین لرنینگ بیشتر در این باره بخوانید). قطعا، استفاده از هوش مصنوعی نیز مشکلات و تبعاتی دارد. سوگیرهای الگوریتمها از جملهی آن معایب و تبعاتاند.
۲. سوگیریهای اجتماعی و شناختی مانعی برای قضاوت و تحلیل درست و منطقی مسائلاند. به همین دلیل، ممکن است تبعات جبرانناپذیری برای افراد، گروهها و حتی کشورها داشته باشند.
۳. اما اشتباه است که اگر فکر کنیم هیچکس نمیخواهد معایب و تبعات استفاده از هوش مصنوعی و یادگیری ماشین را برطرف کند. اتفاقا برعکس، شرکتها، دانشمندان و متخصصان، دولتها و فعالان در تلاشاند تا مطمئن شوند الگوریتمها منصفانه آموزش داده میشوند. به همین دلیل است که Responsible AI به وجود آمده است.
۴. علاوه بر آن، فعالان و رسانهها هم میکوشند تا کاربران را از وجود این سوگیریها آگاه کنند و از آنها بخواهند تا هر چیزی را که در شبکههای اجتماعی میبینند، باور نکنند.
۵. در این میان، نقش متخصصان ماشین لرنینگ را نباید از یاد برد. پس، اگر قصد دارید که وارد حوزهی هوش مصنوعی شوید و پایتون یاد بگیرید و بعد از آن هم آموزش ماشین لرنینگ را بگذرانید، بدانید که باید الگوریتمها را بدون پیشداوری آموزش دهید.
۶. مشکل سوگیری الگوریتمهای شبکههای اجتماعی وجود دارد و مهم است. برای رفع آن مشکل لازم است کاربران و متخصصان با یکدیگر همکاری کنند. یعنی هم ما کاربران باید آگاهانه دربرابر مطالبی که در سوشال مدیا میبینیم، موضع بگیریم و هم متخصصان تلاش کنند تا الگوریتمها را مسئولانه آموزش دهند و بهکار گیرند.


دوره تخصصی یادگیری ماشین
در یک دوره آموزشی متخصص یادگیری ماشین شوید.
از یادگیری ماشین می توان در صنایع مختلف با اهداف مختلف استفاده کرد. ماشین لرنینگ باعث افزایش بهره وری در صنایع می شود، به بازاریابی محصول کمک کرده و پیش بینی دقیق فروش را ساده تر می کند. پیش بینی های دقیق پزشکی و تشخیص ها را تسهیل می کند. دقت در قوانین و مدل های مالی را بهبود می بخشد. به سیستم های توصیه گر، الگوریتم های فرا ابتکاری و حرکت ربات ها کمک خواهد کرد. در بحث فروش میتواند محصولات مناسب تری را به مشتری پیشنهاد دهد( با کمک به تقسیم بندی بهتر و پیش بینی دقیق طول عمر محصولات ) و ...
استفاده از سیستم های ماشین لرنینگ می تواند تا حد زیادی حجم کاری ما را کاهش دهد. به خصوص کارهایی که نیاز به آنالیز حجم عظیمی از داده و تصمیم گیری بر اساس این داده ها را دارد بسیار تسهیل می کند. سیستم های مبتنی بر ماشین لرنینگ ظرفیت انجام کار صد نفر را همزمان دارد و تنها به کمک ماشین ها می توان بدون صرف وقت و انرژی زیاد، کارهای سنگین را انجام داده و در عین حال پول و درآمد بیشتری کسب کرد. ماشین لرنینگ با خودکارسازی فرایندها و صرفه جویی در زمان، به ما کمک می کند تا بتوانیم زمان و انرژی خود را بر تصمیم گیری های پیچیده تری متمرکز کنیم.
ادامه...