



آنچه در این نوشته خواهیم داشت
چالش
هدف از این چالش تشخیص چراغ راهنمایی در تصاویر گرفته شده توسط رانندگان با استفاده از اپلیکیشن Nexar بود. در هر تصویر داده شده، لازم بود “طبقه بندی گر” چراغ راهنمایی را تشخیص داده و قرمز یا سبز بودن آن را مشخص کند. به طور خاص، فقط می بایست چراغ راهنمایی را در جهت رانندگی شناسایی کرد.
این چالش بر اساس شبکه های عصبی پیچشی است، روشی بسیار رایج که در تشخیص تصویر با شبکه های عصبی عمیق مورد استفاده قرار می گیرد. مدل های کوچکتر نمرات بالاتری کسب کردند. علاوه بر این، حداقل دقت لازم برای پیروزی ٩۵ درصد بود.
Nexar تعداد ١٨۶۵٩ تصویر دارای برچسب را به عنوان داده های آموزشی ارائه می داد. هر تصویر با یکی از سه کلاس: بدون چراغ راهنمایی، چراغ قرمز و چراغ سبز برچسب گذاری شده است.
نرم افزار و سخت افزار
برای آموزش مدل ها از Caffe استفاده کردم. دلیل اصلی که Caffe انتخاب شد به دلیل تنوع زیاد مدل های از قبل آموزش دیده آن بود. برای تجزیه و تحلیل نتایج، بررسی داده ها از Python ، NumPy و Jupyter notebook استفاده شد. از نمونه های GPU آمازون برای آموزش مدل ها استفاده شد.
طبقه بندی نهایی
طبقه بندی نهایی در مجموعه آزمون Nexar با اندازه مدل ٨۴/٧ مگابایت به دقت ٩۵/٩۴ درصد دست یافت. فرایند دستیابی به دقت بالاتر شامل تعداد زیادی آزمون و خطاست. در پشت برخی از آن ها منطقی وجود داشت و بعضی دیگر فقط بر اساس حدس و گمان جلو رفتند.
یادگیری انتقال
با تلاش برای تنظیم دقیق (fine-tuning) مدلی که در ImageNet با معماری GoogLeNet از قبل آموزش داده شده بود، شروع کردیم. خیلی به دقت بالای ٩٠ درصد دست یافتیم!
SqueezeNet
اخیرا بیشتر شبکه های منتشر شده بسیار عمیق بوده و پارامترهای زیادی دارند. به نظر می رسید که SqueezeNet بسیار مناسب بوده و همچنین دارای یک مدل از قبل آموزش دیده شده در ImageNet بود.
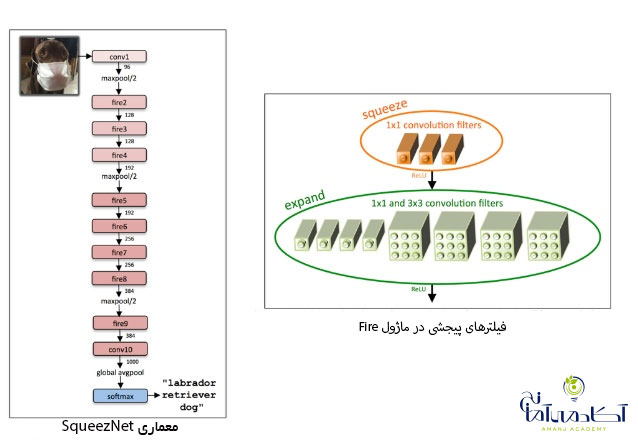
شبکه عصبی با استفاده از فیلترهای پیچشی یک در یک و بعضا سه در سه و همچنین با کاهش تعداد کانال های ورودی به فیلترهای سه در سه، می تواند خود را فشرده سازد.
بعد از مقداری سعی و خطا در تنظیم میزان یادگیری توانستیم مدل از قبل آموزش داده شده را با دقت ٩٢ درصد تنظیم کنیم.

چرخش تصاویر

بیشتر تصاویر مانند تصویر فوق افقی بودند، اما حدود ۴/٢ درصد عمودی بودند و بعضی از آن ها از بالا گرفته شده بودند.



اگرچه این بخش بزرگی از مجموعه داده ها نیست، اما می خواستیم مدل، آن ها را به درستی طبقه بندی کند.
متأسفانه ، هیچ داده ای در تصاویر jpeg که جهت گیری را مشخص می کند، وجود نداشت. به منظور تکمیل تصاویر از آموزش مدل در “میانگین پیش بینی ها” در چرخش های ٠⁰ ، ٩٠⁰ ، ١٨٠⁰ و ٢٧٠⁰ استفاده کردیم. منظور از میانگین پیش بینی ها، میانگین احتمالات تولید شده توسط مدل در هر یک از این چرخش هاست.
برش نمونه ها
در طول آموزش، شبکه SqueezeNet برای اولین بار به طور پیش فرض برش تصادفی تصاویر ورودی را انجام داد و ما آن را تغییر ندادیم. این نوع تقویت داده باعث می شود که شبکه بهتر تعمیم پیدا کند. به طور مشابه، هنگام تولید پیش بینی، چندین برش روی تصویر ورودی ایجاد کرده و میانگین نتایج را به دست آوردیم. از ۵ برش استفاده کردیم. ۴ برش از گوشه و ١ برش از مرکز ( با استفاده از کد Caffe).
چرخش و برش تصاویر پیشرفت بسیار کمی را نشان داد. از ٩٢ درصد به ۴۶/٩٢ درصد.
آموزش اضافی با میزان یادگیری پایین
همه مدل ها بعد از یک نقطه خاص شروع به بیش برازش (overfit) کردند. این امر از طریق مشاهده صعود “تنظیم اعتبار” در برخی نقاط قابل دستیابی است. در این مرحله آموزش را متوقف می کنیم زیرا احتمالا مدل دیگر تعمیم نمی یابد. سعی کردیم آموزش را در نقطه ای که مدل شروع به بیش برازش با نرخ یادگیری ١٠ بار کمتر از سطح اصلی می کند، از سر بگیریم. این امر معمولا دقت را تا ۵/٠ درصد بهبود می بخشد.
داده های آموزشی تکمیلی
در ابتدا داده های خود را به سه مجموعه تقسیم کردم: آموزش (۶۴٪) ، اعتبارسنجی (١۶٪) و آزمون (٢٠٪). بعد از گذشت چند روز به این نتیجه رسیدیم که صرف نظر کردن از ٣۶٪ از داده ها ممکن است خیلی زیاد باشد. در نتیجه مجموعه های آموزشی و اعتبار سنجی را با هم ادغام شده و از مجموعه آزمون برای بررسی نتایج استفاده شد.
مطالعه مقالات زیر در حوزه دیپ لرنینگ به شما توصبه میشود:
رفع اشتباه در داده های آموزش
هنگام تجزیه و تحلیل اشتباهات طبقه بندی گر در اعتبارسنجی ، متوجه اشتباهات فاحشی شدیم. به عنوان مثال، مدل با اطمینان می گفت چراغ سبز است در حالی که داده های آموزش می گفتند چراغ قرمز است. تصمیم گرفتیم این خطاها را در مجموعه آموزش برطرف کنیم. استدلال این بود که این اشتباهات باعث سردرگمی مدل می شوند و تعمیم آن را سخت تر می کنند. حتی اگر مجموعه آزمایش نهایی در پاسخ خود دارای خطای باشد، یک مدل عمومی تر شانس بیشتری برای دستیابی به دقت بالا در بین تصاویر دارد. در یکی از مدل های دارای اشتباه، ٧٠٩ تصویر را برچسب گذاری کردیم. این کار با Python script حدود یک ساعت زمان برد و تعداد خطاها را به ٣٣٧ عدد کاهش داد.
نقص های مدل دیپ لرنینگ
متعادل کردن داده ها
داده ها متعادل نبودند. ١٩ درصد از تصاویر بدون چراغ راهنمایی، ۵٣ درصد در چراغ قرمز و ٢٨ درصد در چراغ سبز بودند. ما سعی کردیم با بیش نمونه گیری ( oversampling) داده های کمتر متداول، مجموعه داده ها را متعادل کنیم؛ اما پیشرفتی حاصل نشد.
جداسازی روز و شب
دریافتیم که تشخیص چراغ راهنمایی در روز و شب بسیار متفاوت است. فکر کردیم که شاید با جداسازی تصاویر روز و شب بتوانیم به مدل کمک کنیم. با در نظر گرفتن میانگین شدت پیکسل ها، جداسازی تصاویر روز و شب بسیار ساده بود. ما دو رویکرد را امتحان کردم که هیچ یک نتیجه بخش نبود:
آموزش دو مدل جداگانه برای تصاویر روز و تصاویر شب
آموزش شبکه برای پیش بینی ۶ کلاس به جای ٣ کلاس، با پیش بینی اینکه آیا روز است یا شب
آموزش طبقه بندی گر برای موارد سخت
٣٠ در صد از تصاویری که طبقه بندی گر برای آن ها از اطمینانی کمتر از ٩٧ درصد برخوردار بود انتخاب کردیم. سپس سعی کردیم طبقه بندی گر را فقط بر روی این تصاویر آموزش دهیم. اما بهبودی حاصل نشد.
نمونه هایی از اشتباهات مدل در تشخیص چراغ راهنمایی

احتمالاً وجود نقطه سبز در نخل که توسط تابش تشعشع بهوجود آمده باعث کی شود مدل به اشتباه چراغ سبز را پیش بینی کند.


این مدل هیچ چراغ راهنمایی را تشخیص نداد در حالی که یک چراغ راهنمایی سبز در تصویر دیده می شود.